Amazon Cloud Search Set up, manage, and scale a search solution for your website or application. Amazon Cloud Search enables you to search large collections of data such as web pages, document files, forum posts, or product information. With a few clicks in the AWS Management Console, you can create a search domain, upload the data you want to make searchable to Amazon Cloud Search, and the search service automatically provisions the required technology resources and deploys a highly tuned search index.
With Cloud Search, you can easily configure with the assistance of the management console. It also lets you scale your application and take control of it. This genius search engine domain seamlessly implements the search in your application.
You will be asked to present a few documents, and you can set up your search domain in no time. With Cloud Search, you need not worry about indexing or query processing yourself. Moreover, you don’t need to rewrite your codes every time you wish to add new features to your website.
Through Cloud Search, you will design a search domain based on your preferences and customer likings.
Cloud Search Features
Faceted search, free text search, Boolean search expressions, customizable relevance ranking, query time rank expressions, field weighting, searching and sorting of results using any field, and text processing options such as tokenization, stop words, stemming, and synonyms are among the features available in Amazon Cloud Search for indexing and searching both structured data and plain text. For document changes, it also enables near-real-time indexing. The following are some of the new features:
· Autocomplete suggestions
· Highlighting
· Geospatial search
· New data types: date, double, 64 bit signed int, LatLon
· Dynamic fields
· Index field statistics
· Sloppy phrase search
· Term boosting
· Enhanced range searching for all field types
· Search filters that don’t affect relevance
· Support for multiple query parsers: simple, structured, lucene, dismax
. Query parser configuration options
. Great scalability features
. Supports around 34 language
. Multiple zone options
. Controls ranking of search results
Accessing Amazon Cloud Search
You can access Amazon Cloud Search through the Amazon Cloud Search console, the AWS SDKs, or the AWS CLI.
. You can quickly upload files, perform test searches, and build, manage, and monitor your search domains using the Amazon Cloud Search dashboard. The interface offers a central command post for continuous control of your search domains and is the simplest way to get started with Amazon Cloud Search.
. The AWS SDKs support all of the Amazon Cloud Search API operations, making it easy to manage and interact with your search domains using your preferred technology. The SDKs automatically sign requests as needed using your AWS credentials.
. To make setting up search domains, adding the data you wish to search, and submitting search queries simple, the AWS CLI covers all of the Amazon Cloud Search API actions. Using your AWS credentials, the AWS CLI automatically signs requests as necessary.
Regions and Endpoints for Amazon CloudSearch
Amazon Cloud Search offers domain-specific endpoints for accessing the search and document services as well as regional endpoints for the configuration service.
Your search domains are created and managed using the configuration service. The endpoints for the region-specific configuration services have the following format: cloudsearch.region.amazonaws.com. Take cloudsearch.us-east-1.amazonaws.com as an illustration. See Regions and Endpoints in the AWS General Reference for a list of the most recent supported regions.
To access the Amazon CloudSearch search and document services, you use separate domain-specific endpoints:
http://doc-domainname-domainid.us-east-1.cloudsearch.amazonaws.com—a domain’s document service endpoint is used to upload documentshttp://search-domainname-domainid.us-east-1.cloudsearch.amazonaws.com—a domain’s search endpoint is used to submit search requests
How Search Works
The collection of data you wish to search, might be made up of structured data that follows a certain data model, semi-structured documents like those produced in mark-up languages like XML, or unstructured full-text documents. A document is used to represent any object you wish to be able to search, such as a forum post or web page. Each document has a distinct ID as well as one or more fields that hold the information you wish to search for and include in the results.
You must submit a batch of documents in either JSON or XML to your search domain in order to make your data searchable. Then, in accordance with the configuration settings for your domain, Amazon CloudSearch creates a search index from the data in your documents. You submit queries to this index in order to locate the documents that match a certain set of search parameters.
You submit updates as your data changes to add, modify, or remove documents from your index. Continuous updates are made in the order they are received.
Indexing in Amazon CloudSearch
Amazon CloudSearch requires the following data to create a search index from your data:
- Which document fields do you want to search?
- Which document field values do you want to retrieve with the search results?
- Which document fields represent categories that you want to use to refine and filter search results?
- How should the text within a particular field be processed?
By defining indexing options in your domain setup, you specify this metadata. You may set the fields that are included in the search index and manage how you can utilize those fields using indexing options.
There is a one-to-one mapping between document fields and the fields in your Amazon CloudSearch index, therefore you must set up an index field for each document field that appears in your data. In addition to the name of the index field, you specify:
- The index field type
- Whether the field is searchable (
textandtext-arrayfields are always searchable) - Whether the field can be used as a category (facet)
- Whether the field value can be returned with the search results
- Whether the field can be used to sort the results
- Whether highlights can be returned for the field
- A default value to use if no value is specified in the document data.
Facets in Amazon CloudSearch
You may narrow and filter search results by using facets, which are index fields that indicate categories. You may ask Amazon CloudSearch for facet information when submitting search requests to learn how many hits have the same value for a certain aspect. This data can be shown alongside the search results and used to provide consumers the option to interactively narrow their searches. (This is frequently referred to as faceted search or faceted navigation.)
Any date, literal, or numeric field that has faceting enabled in your domain settings can be considered a facet. Amazon CloudSearch counts the number of finds that have the same value for each facets. For specific subsets of the facet values, you can specify buckets to calculate facet counts. The facet results only contain buckets that have matches.
Text Processing in Amazon CloudSearch
When indexing, the language-specific analysis strategy set for the field is used to process the text and text-array field contents. An analysis scheme defines any stopwords or synonyms to be taken into consideration during indexing and governs how the text is normalized, tokenized, and stemmed. Each supported language is given a default analysis strategy by Amazon CloudSearch.
Sorting Results in Amazon CloudSearch
By creating expressions that compute unique values for each page that satisfies your search criteria, you may define how search results are prioritized. You might, for instance, build an expression that considers the popularity field value as well as the standard relevance score determined by Amazon CloudSearch. Expressions are basic mathematical constructs that employ common mathematical operators and operations. Expressions may make use of int and double fields, other expressions, the relevance score (_score) and epoch time (_time) of a document. The expression(s) you want to use to order the search results are specified when you submit a search request. Additionally, you may use phrases as search criteria.
The relevance _score of a document describes how pertinent a given search result is to the search query. The frequency of the search phrases in a document in relation to other documents in the index is taken into consideration by Amazon CloudSearch when calculating the relevancy score.
Search Requests in Amazon CloudSearch
You send HTTP/HTTPS GET requests for searches to the search endpoint of your domain. There are several choices you may choose from to limit your search, ask for facet information, manage ranking, and select what you want to see in the results. JSON or XML search results are available. Results are typically returned by Amazon CloudSearch in JSON format.
When you submit a search request, Amazon CloudSearch performs text processing on the search string. The search string is processed to:
- Convert all characters to lowercase
- Split the string into separate terms on whitespace and punctuation boundaries
- Remove terms that are on the stopword list for the field being searched.
- Map stems and synonyms according to the stemming and synonym options configured for the field being searched.
Following the completion of this preprocessing, Amazon CloudSearch searches the index for the search keywords and locates all of the documents that match the request. This set of search results is processed by Amazon CloudSearch to find matching documents by sorting, filtering, and computing facets. The response is then sent back by Amazon CloudSearch in JSON or XML.
By default, Amazon CloudSearch presents search results that are ranked by the relevance scores of the hits. As an alternative, you may provide in your request the index field or phrase you wish to use to order the results. For instance, you could wish to arrange results based on a price index field or a popularity expression.
Automatic Scaling in Amazon CloudSearch
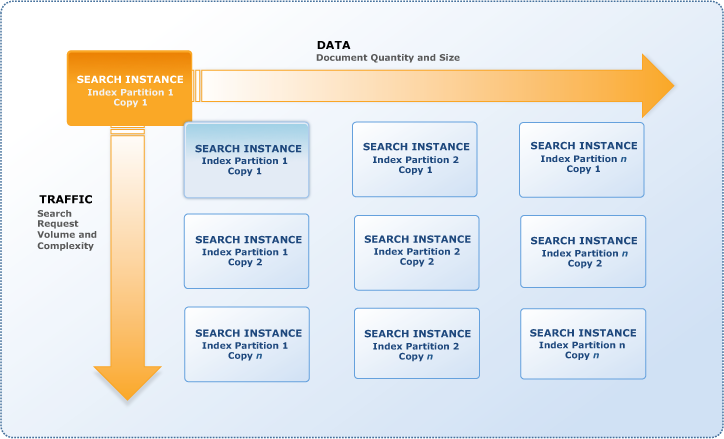
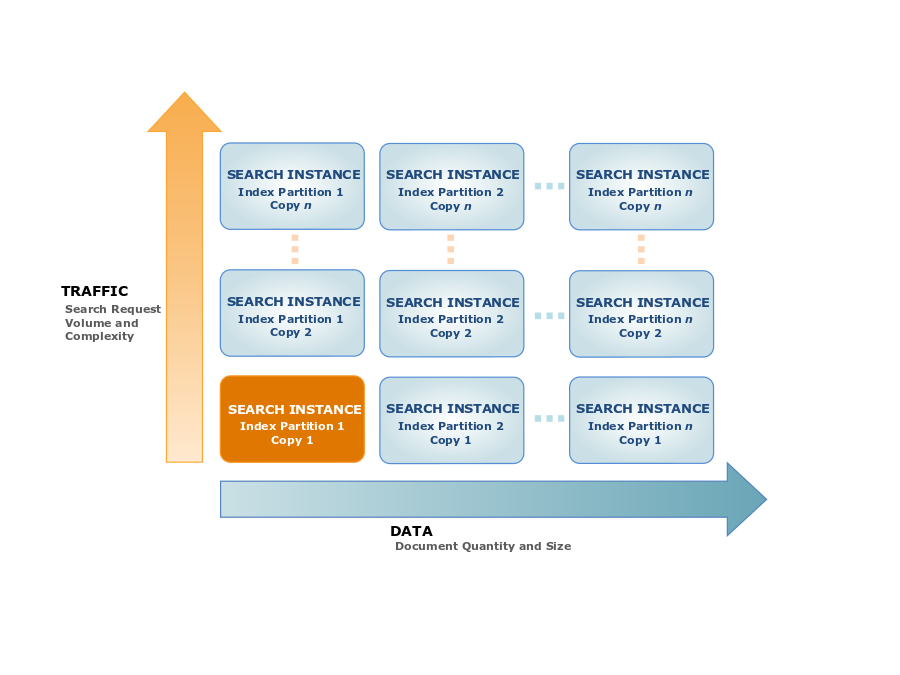
One or more search instances, each with a limited amount of RAM and CPU resources for indexing data and handling queries, make up a search domain. The number of search instances a domain requires depends on the collection of documents you have, as well as the quantity and complexity of your search queries.
In order to provide low latency, high throughput search performance, Amazon CloudSearch can calculate the size and quantity of search instances needed. When you upload your data and set up your index, Amazon CloudSearch creates the necessary initial search instance type while building an index. Amazon CloudSearch can scale to handle the number and complexity of search requests as well as the quantity of data submitted to the domain as you use it.
One instance is deployed for the domain when you create a search domain. You always have at least one instance of your domain, as seen in the following image. As the amount of data or traffic grows, Amazon CloudSearch automatically expands the domain by adding instances.
Upgrading of Software
Cloud Search Amazon directly alerts the software for any new updates. You do not have to worry about manually updating them whenever there is a new feature released. Although in a few instances, the updating process can get delayed by the Amazon Cloud Services.
High Performance of Cloud Search
When picking a search engine, one of the most crucial factors to consider is performance. One of the primary reasons many engineers migrate from a self-built search mechanism to an outside hosted search solution like AWS Cloud Search is faster data delivery. Automatic indexing, horizontal — vertical scalability, and distributed data offer you a leg up on the competition when it comes to providing your data with minimal latency and maximum speed.
Service Provided
Cloud Search is fully managed and developed by Amazon Cloud Service that manages the complete functionality of this software.
Integration with
It is essential to know that Cloud search can integrate with which tools. Amazon Cloud search can integrate with the BindPlane tool.
Backup Index
CloudSearch, on the other hand, manages the index backup process as a whole automatically. Unlike Elasticsearch, you need not manually restore data and backup your vital information.
Data Security and Privacy
Security and privacy is an essential requirement in any tool whenever it comes to data for every user. So, any unauthenticated user could not access someone’s data.
Amazon Cloud search offers an IAM-based access control mechanism. This mechanism controls the access of users to use its features and resources, or we can say that it grants the users access. IAM stands for Identity and Access Management. It assigns different roles to users at the permission level.
Data Import/Export
Data processing is an essential features of AWS-based search services. The existing data should be imported into the search engine when it needs to be searched. Cloud search provide data handling facility for diverse application.
Cost of Service
Cloud search is a paid search solution, which is not free to use. It charges on an hourly basis, which depends on the size of user searches. This means it depends on the search instance size. Cloud search imposes the charges in dollars, which could be like –
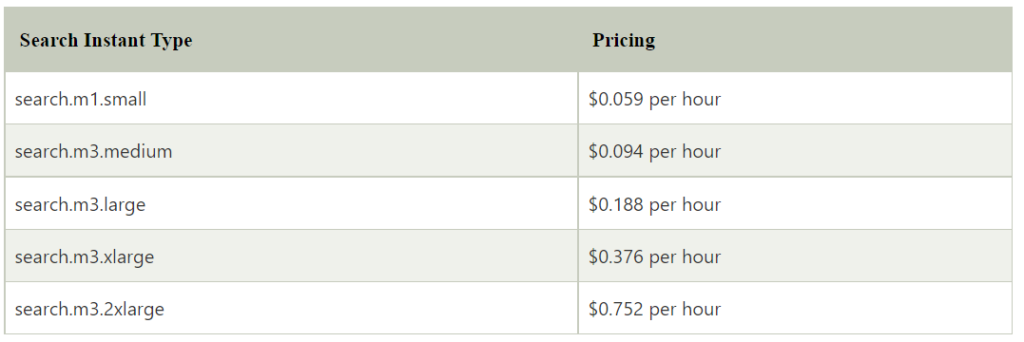
Which companies use Amazon Cloud Search?
Cloud search is excellent AWS-based tool and used for quick to search the data. This is demanding technology and choice of several companies. There are many companies that use cloud search these companies are Bizo, Smart Insight Corporation, News UK, Search Technologies, 8KMiles, Vuzz Inc., SitePX, Company Check, Voce Communication, PBS…