Search is an essential part of any significant data-driven website or app. Without search or even a suitable searching mechanism your data is virtually inaccessible from the reach of your users.
To put it another way, the implementation of your search engine is one of the most important aspects of your web application. This gets consumers to the material they want in the quickest and most effective way possible.
We will talk about CloudSearch, one of Amazon’s search tools.
Document History for Amazon CloudSearch
This topic describes important changes to Amazon CloudSearch.
Relevant Dates to this History:
- Current product version—2013-01-01.
- Latest product release—6 January 2021.
- Latest documentation update—6 January 2021.
Enforce HTTPS – You can now require that all requests to your Amazon CloudSearch domain arrive over HTTPS (13 November 2019).
Support for resource tagging – Amazon CloudSearch added support for resource tagging (10 February 2016).
AP (Seoul) support – Amazon CloudSearch added support for the AP (Seoul) ap-northeast-2 region.(28 January 2016).
Integration with Amazon CloudWatch and support for index field statistics – You can now use Amazon CloudWatch to monitor your Amazon CloudSearch domains. CloudWatch is a monitoring service for AWS cloud resources and the applications you run on AWS. Amazon CloudSearch automatically sends metrics to CloudWatch so that you can gather and analyze performance statistics. You can monitor these metrics by using the Amazon CloudSearch console, or by using the CloudWatch console, AWS CLI, or AWS SDKs. There is no charge for the Amazon CloudSearch metrics that are reported through CloudWatch.You also can now retrieve statistics against facet-enabled numeric fields. Amazon CloudSearch can return the following statistics against indexed numeric fields in the documents: count, min, max, mean, missing, stddev, sum, and sumOfSquares.(5 March 2015)
Support for M3 instance types – You can now use M3 instances to power your Amazon CloudSearch domains. Amazon CloudSearch now supports the following instance types for newly created domains: m1.small, m3.medium, m3.large, m3.xlarge, and m3.2xlarge.(10 February 2015).
Support for Dynamic Fields – Dynamic fields provide a way to index documents without knowing in advance exactly what fields they contain. A dynamic field’s name defines a pattern that contains a wildcard (*) as the first, last, or only character. Any unrecognized document field that matches the pattern is configured with the dynamic field’s indexing options.(11 December 2014)
These are the recent features implemented by Amazon CloudSearch
What is Amazon CloudSearch?
Amazon CloudSearch is a fully managed service in AWS (Amazon Web Services) cloud that makes it simple and cost-effective to set up, manage, and scale a search solution for your website or application. The fundamental text search engine of Amazon CloudSearch is Apache Solr.
Amazon CloudSearch features:
- Autocomplete suggestions
- Highlighting
- Geospatial search
- New data types: date, double, 64-bit signed int, LatLon
- Dynamic fields
- Index field statistics
- Sloppy phrase search
- Term boosting
- Enhanced range searching for all field types
- Search filters that don’t affect relevance
- Support for multiple query parsers: simple, structured, Lucene, dismax
- Query parser configuration options
How to use AWS Cloudsearch?
This are the steps to use AWS Cloudsearch, let’s follow them:
Step 1- Open console.aws.amazon.com in a browser with good compatibility.
Step 2- There you will notice Cloudsearch option and after selecting it selects to create a search domain. The search domain will encapsulate the data and server resources that processed data and search requests.
Step 3- After this, the next step will be the way the user will configure the index field. After the selection, the field can be modified if needed with the help of the console.
Step 4- The resources will be provisioned for the new domain after the domain is ready the documents are uploaded which are to be used.
Step 5- If the user wants to upload the predefined data the option is provided. This can do with the help of either Jayson or XML.
Step 6- The next step will a review set which will notify the number of documents upload.
Step 7- The next step will run a test search which will help to submit the queries or some specific texts.
Step 8- After the submission of the query, the search test displays all the returnable data or each hit.
Step 9- The user will then submit the search and document upload requests through AWS SDK and AWS CLI.
Step 10- Lastly, the user can practice on Amazon Console before indulging in actual Cloudsearch.
How does Search work?
The collection of data that you want to search (also known as your corpus) can be made up of unstructured full-text documents, semi-structured documents such as those formatted in mark-up languages like XML, or structured data that adheres to a strict data model. Each item that you want to be able to search for (for example, a forum post or a web page) is represented by a document. Every document has a unique ID and one or more fields containing the data you want to search for and include in the results.
To make your data searchable, create a batch of documents in JSON or XML and upload it to your search domain. Amazon CloudSearch then creates a search index from your document data based on the configuration options for your domain. You submit queries to this index in order to find documents that meet specific search criteria.
You submit updates to add, change, or delete documents from your index as your data changes. Updates are applied in the order in which they are received.
What advantages does Amazon CloudSearch have?
Amazon CloudSearch is a fully managed search service that automatically scales to meet the volume of data and complexity of search queries to provide quick and accurate results. Customers can use Amazon CloudSearch to provide search functionality without worrying about managing hosts, scalability of traffic and data, redundancy, or software packages. Users are only charged for the resources they use on an hourly basis. When compared to owning and managing your own search environment, Amazon CloudSearch can offer a significantly lower total cost of ownership.
Accessing Amazon CloudSearch
You can access Amazon CloudSearch through the Amazon CloudSearch console, the AWS SDKs, or the AWS CLI.
- The Amazon CloudSearch console enables you to easily create, configure, and monitor your search domains, upload documents, and run test searches. Using the console is the easiest way to get started with Amazon CloudSearch and provides a central command center for the ongoing management of your search domains.
- The AWS SDKs support all of the Amazon CloudSearch API operations, making it easy to manage and interact with your search domains using your preferred technology. The SDKs automatically sign requests as needed using your AWS credentials.
- The AWS CLI wraps all of the Amazon CloudSearch API operations to provide a simple way to create and configure search domains, upload the data you want to search, and submit search requests. The AWS CLI automatically signs requests as needed using your AWS credentials.
High Performance of CloudSearch
One of the most important factors to consider when selecting a search engine is performance. One of the primary reasons many engineers migrate from a self-built search mechanism to an outside hosted search solution like AWS CloudSearch is faster data delivery. When it comes to providing your data with minimal latency and maximum speed, automatic indexing, horizontal — vertical scalability, and distributed data give you an advantage over the competition.
Benefits of Amazon Cloudsearch
- Simple
AWS CloudSearch domains can be created and managed using the AWS Management Console, AWS CLI, and AWS SDKs. Simply apply a purpose to a sample of your data, and Amazon CloudSearch will automatically suggest a way to organize your domain’s indexing options.
The user will be able to easily add or delete index fields as well as change search options such as faceting and light. You do not need to re-upload your data if your configuration changes.
- Scalable
Amazon CloudSearch provides robust autoscaling across all search domains. As the volume of your data or questions changes, AWS CloudSearch will scale your search domain’s resources up or down as needed.
If you recognize that you simply want a lot of capability for bulk uploads or anticipate a surge in search traffic, the user will be able to scale.
- Dependable
AWS CloudSearch automates the monitoring and recovery of your search domains. Once Multi-AZ is enabled, Amazon CloudSearch provision and maintains resources for an exploration domain in two availability Zones to ensure high availability.
Updates are automatically applied to the search instances in each useful Zone. Search traffic is distributed across each availability Zone, and instances in either zone can handle the total load in the event of a failure.
- High Efficiency
Through automatic scaling and horizontal and vertical autoscaling, AWS CloudSearch ensures low latency and high turnout performance even at massive scale.
- Completely Managed
Amazon CloudSearch can provide a fully managed custom search service. Hardware and code provisioning, setup and configuration, code maintenance, data partitioning, node observance, scaling, and data durability are all handled for you.
So that was the AWS Cloudsearch Tutorial. We hope you found our explanation helpful.
Getting Started with Amazon CloudSearch
To start searching your data with Amazon CloudSearch, you simply take the following steps:
- Create and configure a search domain
- Upload and index the data you want to search
- Send search requests to your domain
The Limitations of Amazon CloudSearch
- The maximum batch size is 5 MB.
- You can load one document batch every 10 seconds (approximately 10,000 batches every 24 hours), with each batch size up to 5 MB.
- The maximum document size is 1 MB.
- Documents can have no more than 200 fields.
- Up to 50 expressions can be configured for a domain.
Conclusion
Amazon CloudSearch uses sturdy cryptologic strategies to manifest users and forestall unauthorized access to your domains. Amazon CloudSearch supports HTTPS and integrates with Identity and Access Management (IAM) to manage access to the CloudSearch configuration service and every domain’s document, search, and recommend services.
Python Programming for Serverless functions:
import json
import requests
import boto3
def lambda_handler(event, context):
print("Event",event)
for record in event['Records'] :
movie_name = record['body']
url = 'https://www.omdbapi.com/?t={}&apikey=7b57508f'
response = requests.get(url.format(movie_name))
data = response.json()
# upload the poster to S3
image_url = data['Poster']
r = requests.get(image_url, stream=True)
session = boto3.Session()
s3 = session.resource('s3')
bucket_name = 'sowparni-imdb-bucket'
key = data['Title'] + '-' + data['Year']
bucket = s3.Bucket(bucket_name)
bucket.upload_fileobj(r.raw, key)
# publish the output json to sns
sns_topic_arn = 'arn:aws:sns:us-east-2:458146298847:sowparni-movie-sns-topic'
output_json = {
'Movie Name' : data['Title'],
'Release Date' : data['Released'],
'Director' : data['Director'],
'Actors' : data['Actors'],
'Poster' : f"https://{bucket_name}.s3.us-east-2.amazonaws.com/{key}"
}
client = boto3.client('sns')
response = client.publish(
TargetArn=sns_topic_arn,
Message=json.dumps({'default': json.dumps(output_json)}),
MessageStructure='json'
)
return(output_json)
Steps:
Create a Serverless Lambda Function with runtime as Python3.7
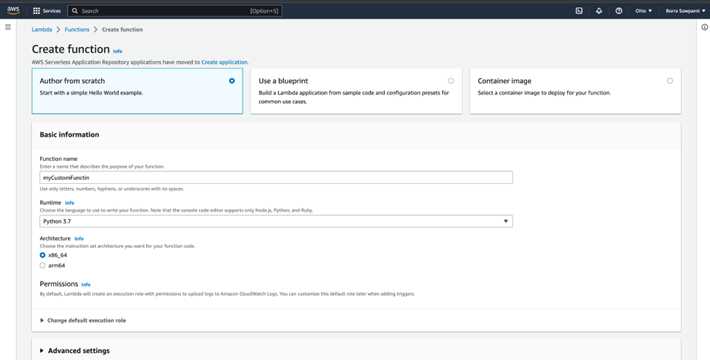
Add Required S3, SQS, SNS permissions

Add code to the Lambda

Create S3 Bucket

Add S3 Bucket permission to access files from the web

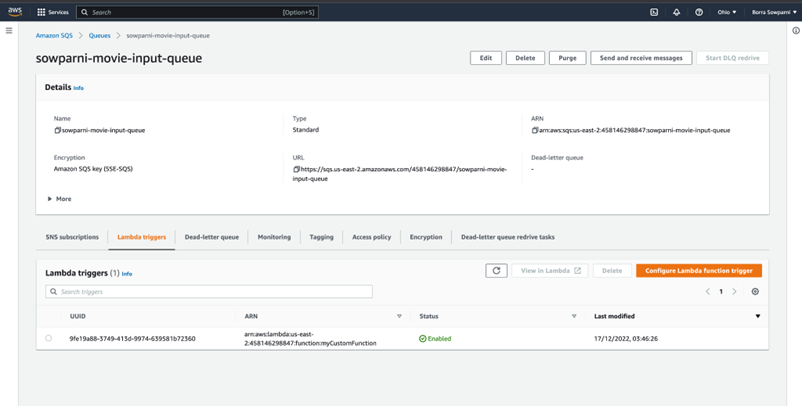
Create SQS
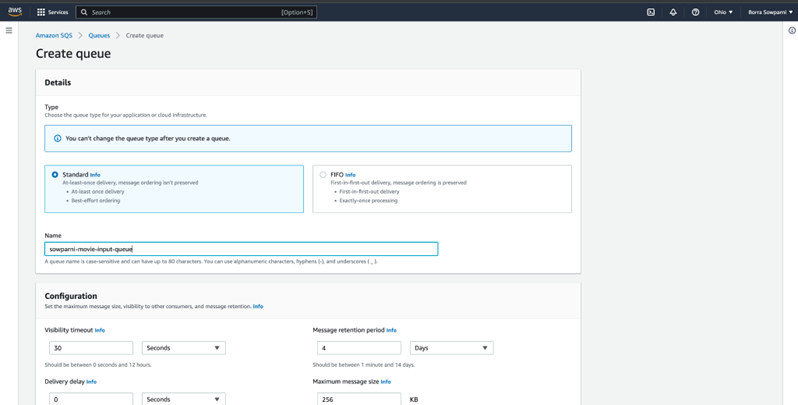
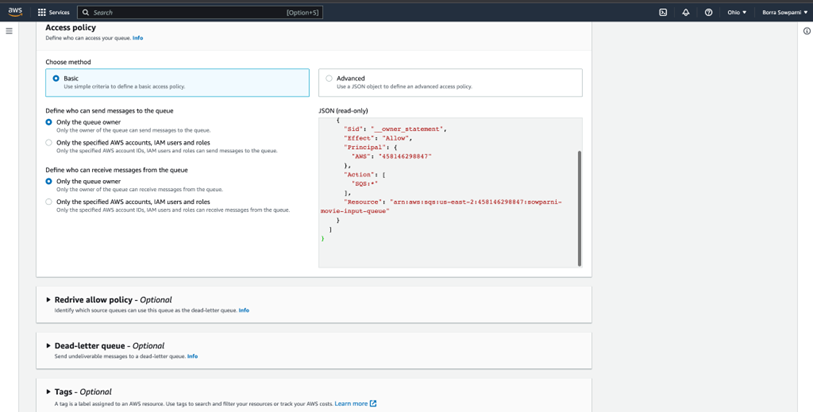
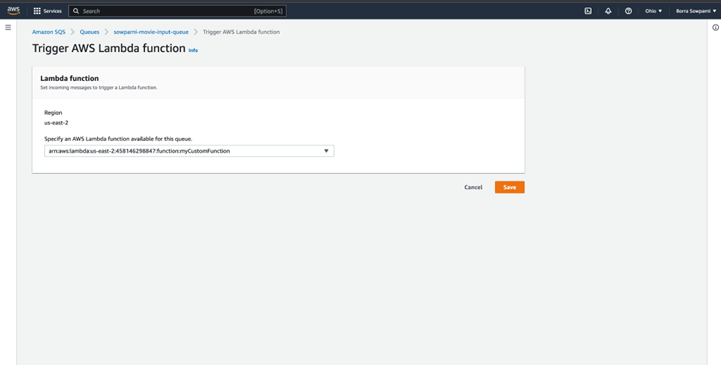
Add trigger from SQS to lambda serverless function

Create SNS topic
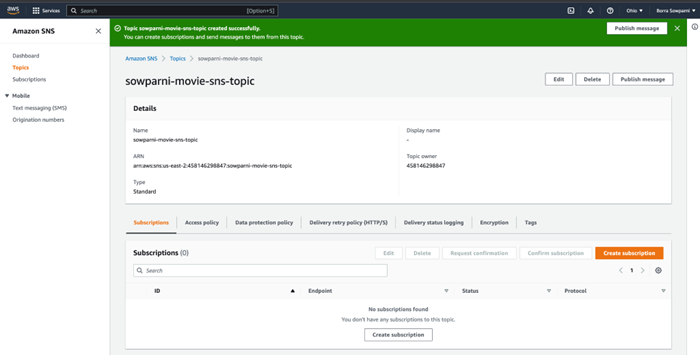
Add a Subscription
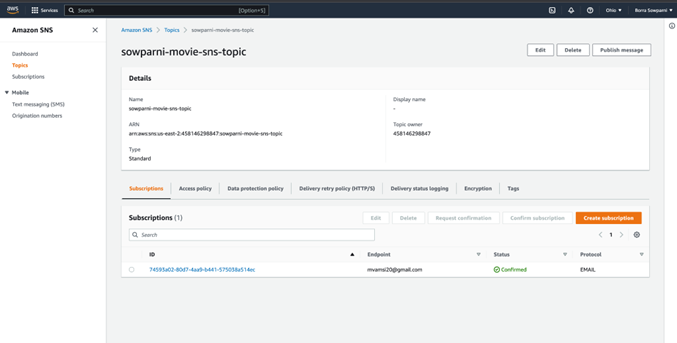
Testing – Send a message to the SQS and pass any movie name as input

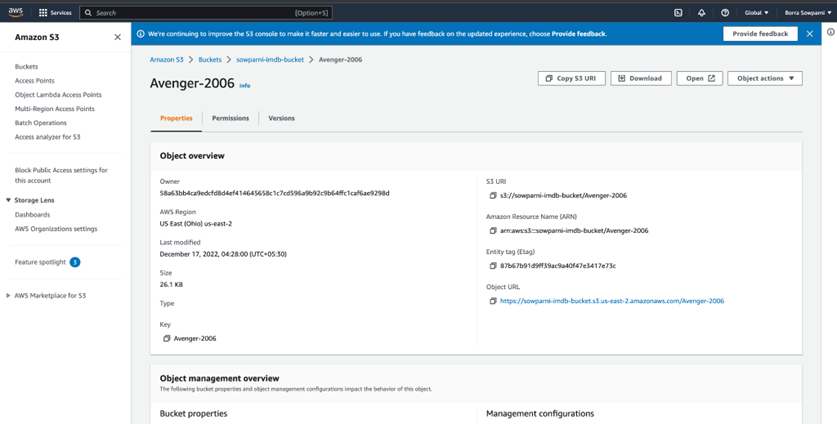
Result:
Movie Poster uploaded in S3 Bucket
Automated mail with the details of the movie

Outlook for the python code:
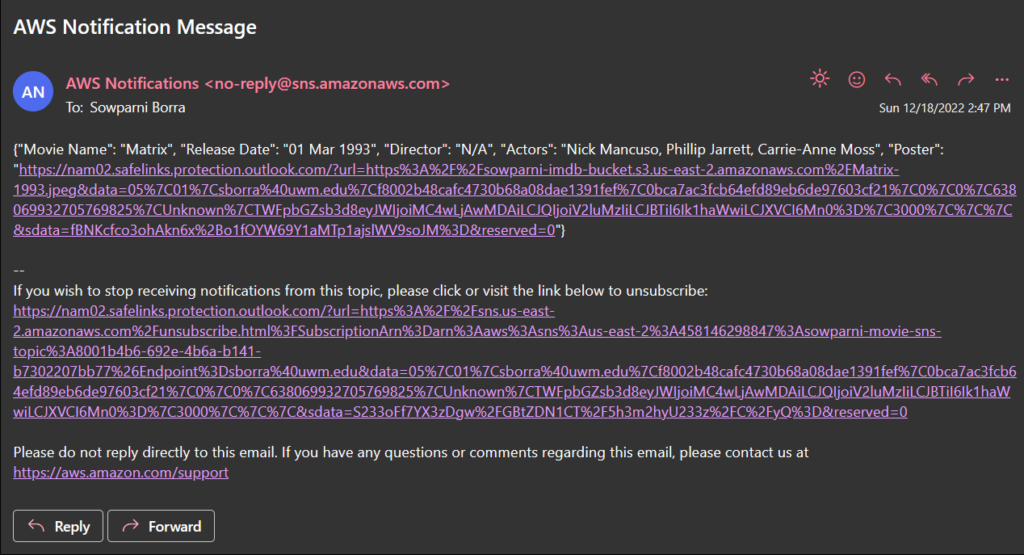
If we open the link from the outlook:
