This post will serve as a detailed how-to guide for backing up and restoring your data using AWS Backup and going through all of the steps involved in running backups using the AWS web console.
Step-By-Step Guide to Backing Up Your Resources
Creating a Backup Vault
Before backing up your resources, you have to prepare a storage repository.
Since all of your backups will be stored in a vault, you must decide whether you want to use the default one or a new one dedicated specifically to backup jobs—perhaps because you want to create a logical separation of resources.
To do this, start by opening AWS Backup using the web UI and going to “Backup vaults.”
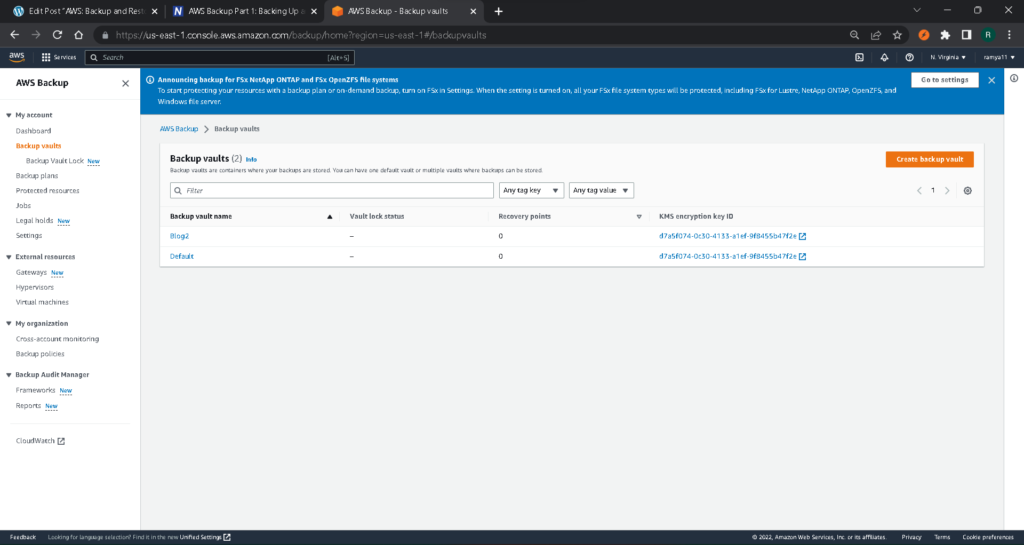
If you decide to use the default vault, you can skip this step. We’re going to create a new vault that we’ll be using later by simply clicking on “Create Backup vault.
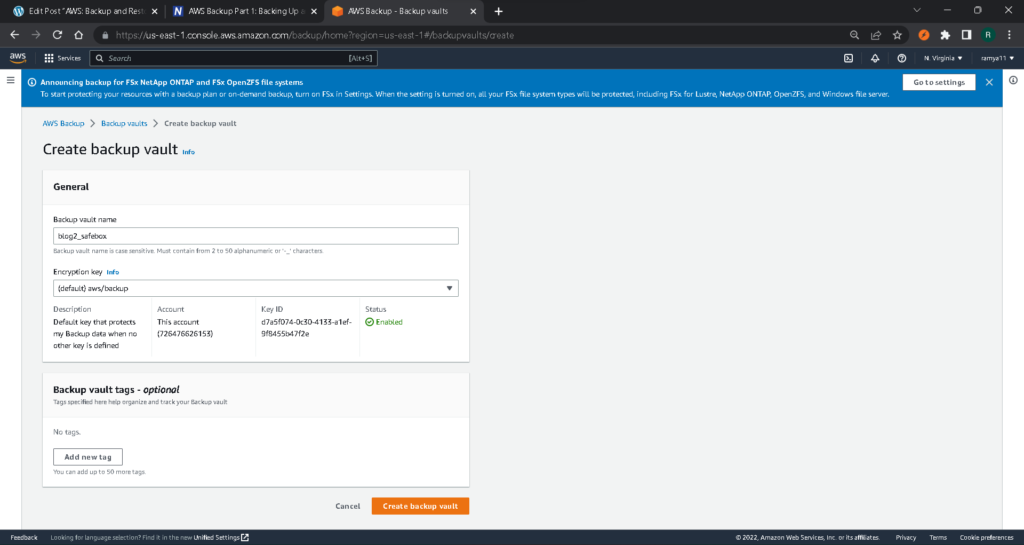
After providing the desired backup vault name, you’ll need to choose the Key Management Service (KMS) encryption master key (which is necessary for safeguarding your other encryption keys) and, if you want to, add some backup vault tags. Adding tags is a good idea if you have multiple vaults in use.
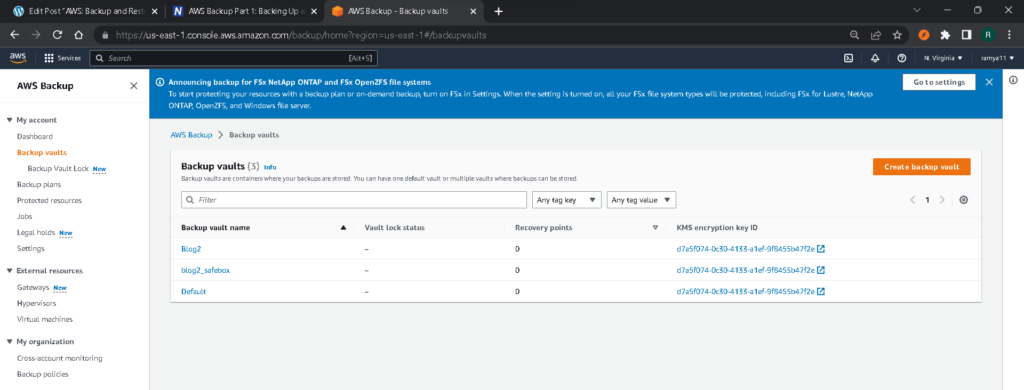
Once you have completed these steps, click on “Create Backup vault.” Now, if you go back to the backup vaults page, you will see that the new vault is ready to be used.
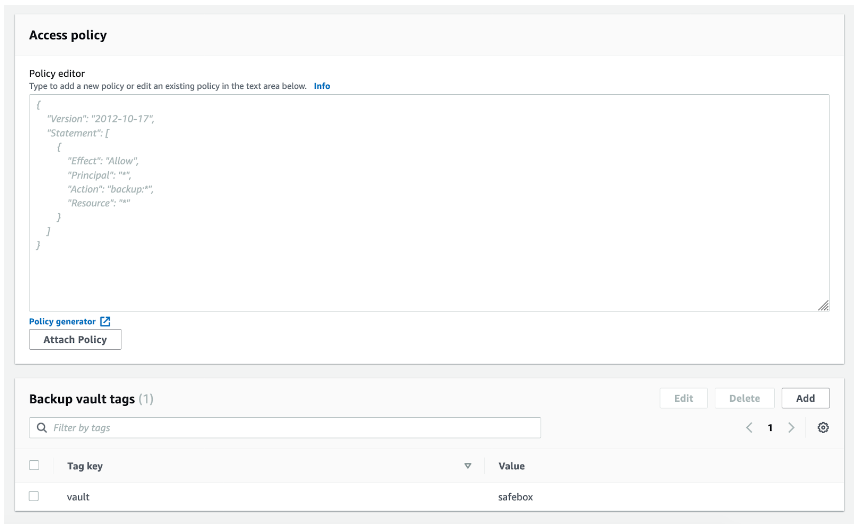
If you open the vault, you will see some basic information inside, such as the vault creation date, the encryption key being used, and the backups that have been performed (since we haven’t done any yet, these are not showing up in the screenshot above).
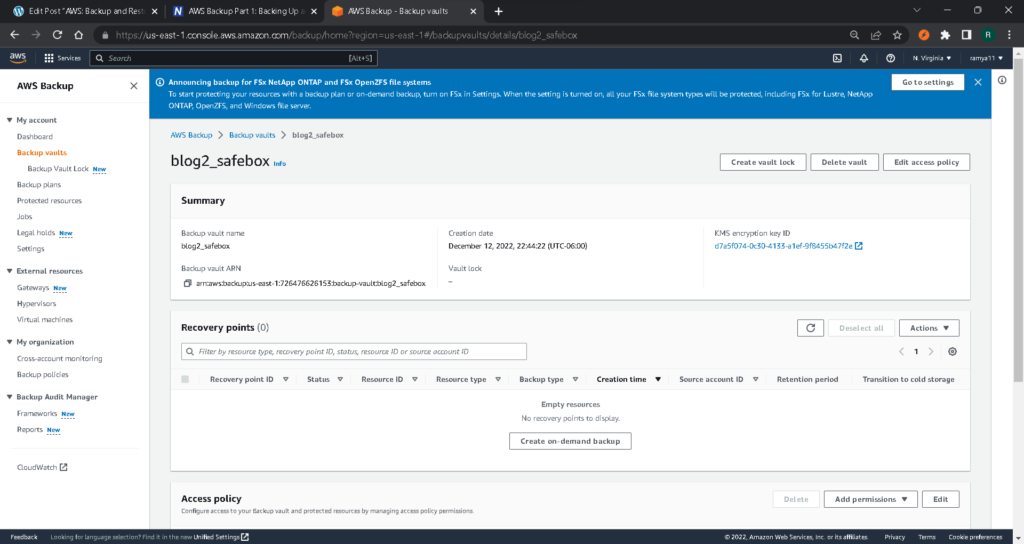
You will also see both the tags (which can be added or removed here) and the access policy on this screen. The access policy allows you to specify who has access to the backups in the vault and what actions they can perform on them. When you first launch AWS Backup, this policy will be blank.
Creating a Backup Plan
Now that the vault is ready, you can create a backup plan. Open the “Backup plan” tab and click on “Create Backup plan.”
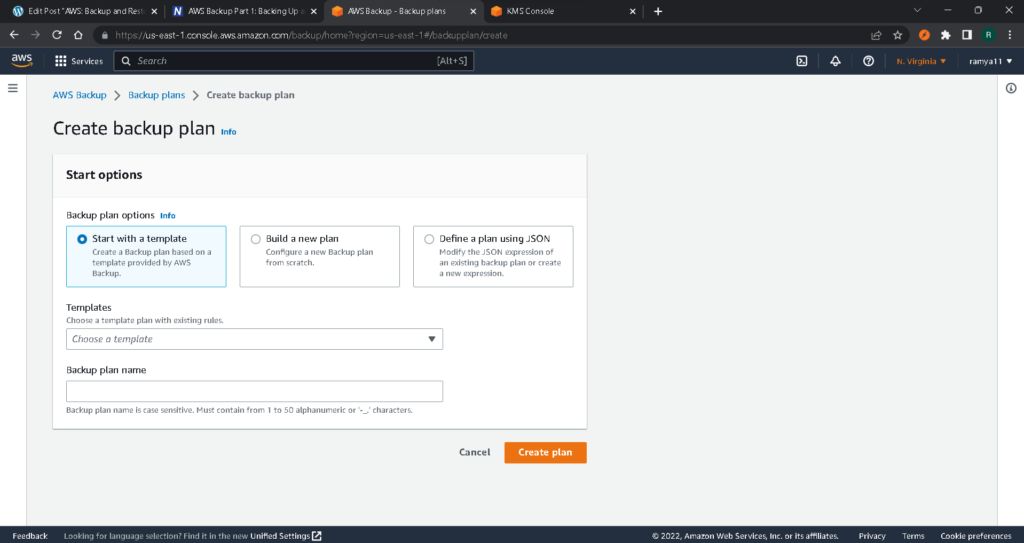
There are three different backup plan options to choose from, as you can see in the screenshot below.
Backup plans use time-based backups. You will need to specify a backup window—the time at which all of your backups jobs will occur. You can use the default time, which is set at 5AM UTC.
Historically, companies have relied heavily on generational backups such as grandfather-father-son (GFS) backup rotation schemes. GFS backups work by keeping multiple backup cycles (typically, there are three), such as daily, weekly, and monthly cycles. Each of these backup cycles is rotated separately, and, some of them, such as the yearly or monthly ones, are backed up offsite as well in order to comply with AWS Disaster Recovery (DR) requirements.
Even though AWS Backup works by creating time-based backups, you can use it to create generational backups if your business needs require them. How to do this will be explained later in this blog.
Backup Plan Option 1: “Build a New Plan”
Let’s look at each of the three backup plan options in detail. We’ll start with building a new plan from scratch, since it requires the most work. This option allows you to specify all of the backup configuration details, either by using the recommended defaults or by choosing the specific ones that will best suit your business needs.
Start by naming your backup plan. The name should be something that relates to the resource (or group of resources) being backed up. For instance, if you are making a backup plan for all your RDS instances, you can name it “database backups.”
Next, configure a backup rule. Each AWS backup plan can have one or more rules, each with its own configuration.
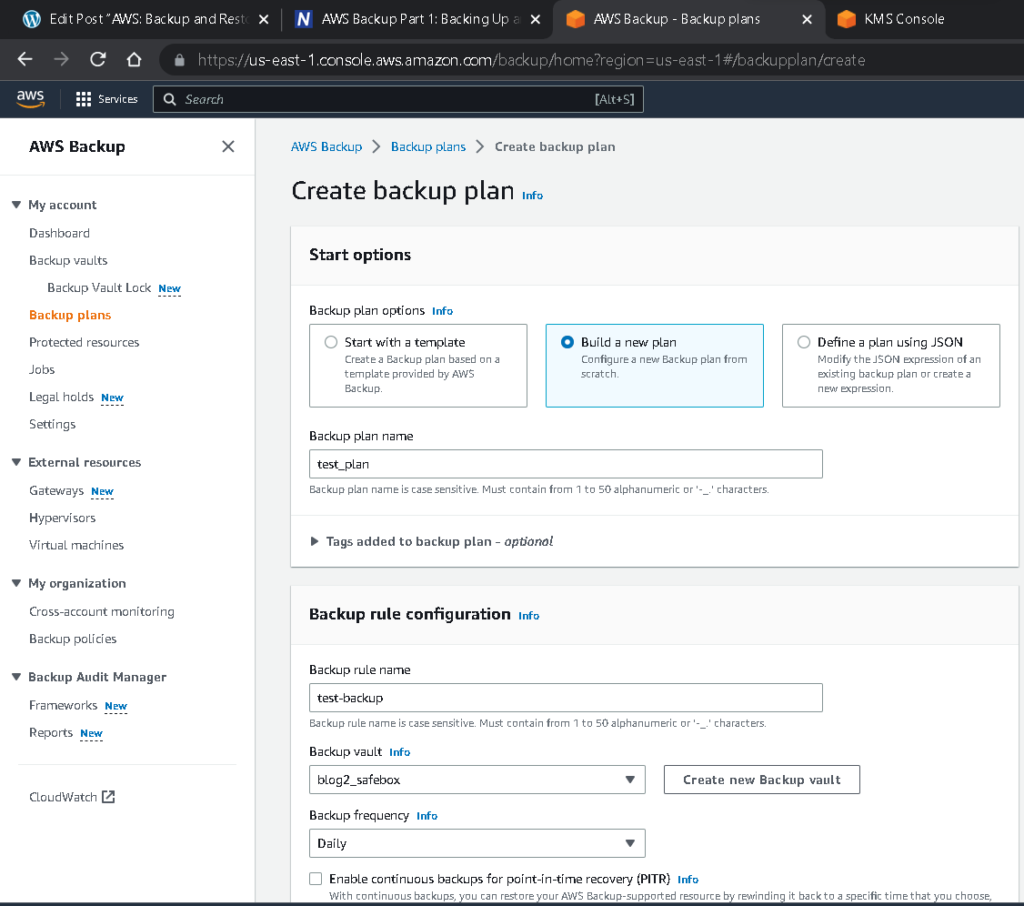
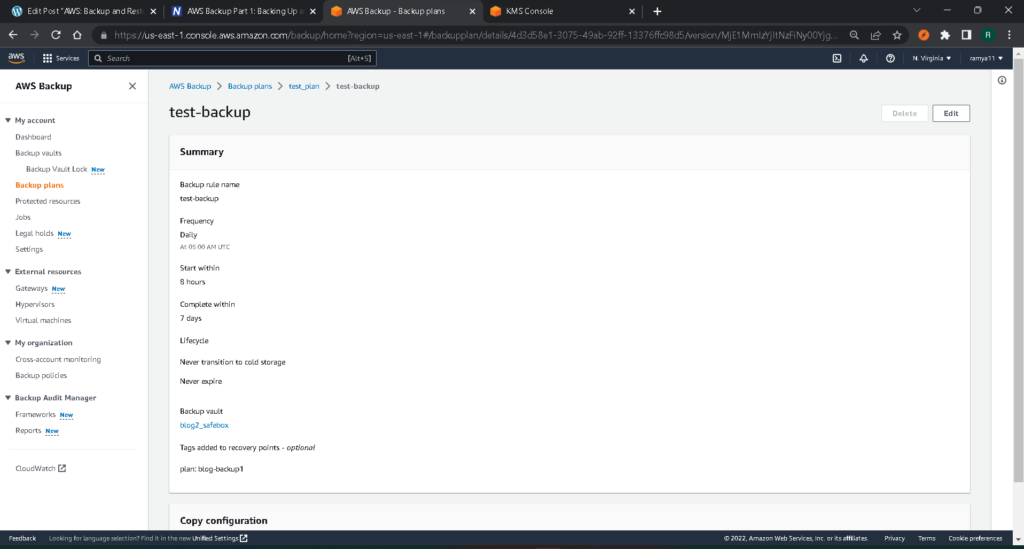
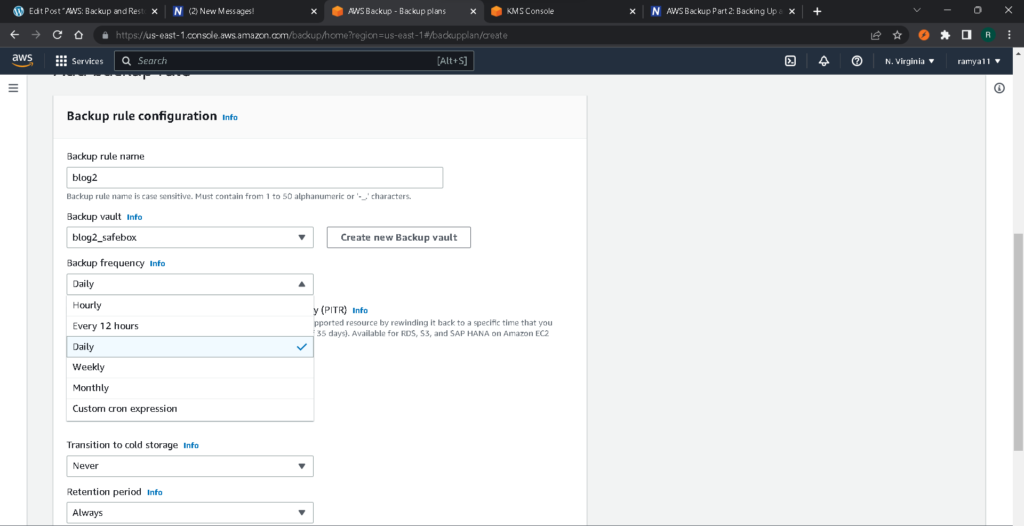
Backup rules run on set schedules. We opted for a daily schedule here, but you can also choose weekly, monthly, every 12 hours, or a schedule defined by a custom cron expression. You’ll also need to set up a backup window. Let’s say you don’t want to use the default time. You’d prefer a backup window that starts at 8AM UTC and is open for 2 hours (the minimum is 1 hour, but you can set it as high as 12 hours if needed).
Start by defining the life cycle, a process which consists of two parts. The first is a transition to cold storage (AWS Glacier). Moving backups allow you to save money, so we’re going to choose to move all of the backups to storage after 4 weeks. The second part of defining the life cycle involves data expiration, a business decision that depends on the information you are storing and the kinds of cost savings you are looking to achieve. In our case, we’re choosing to keep the backups for 5 months. After that, they can be removed. Some businesses have to keep backups much longer to stay in compliance with regulations; in fact, they may even skip the data expiration step completely, choosing to retain all backups indefinitely.
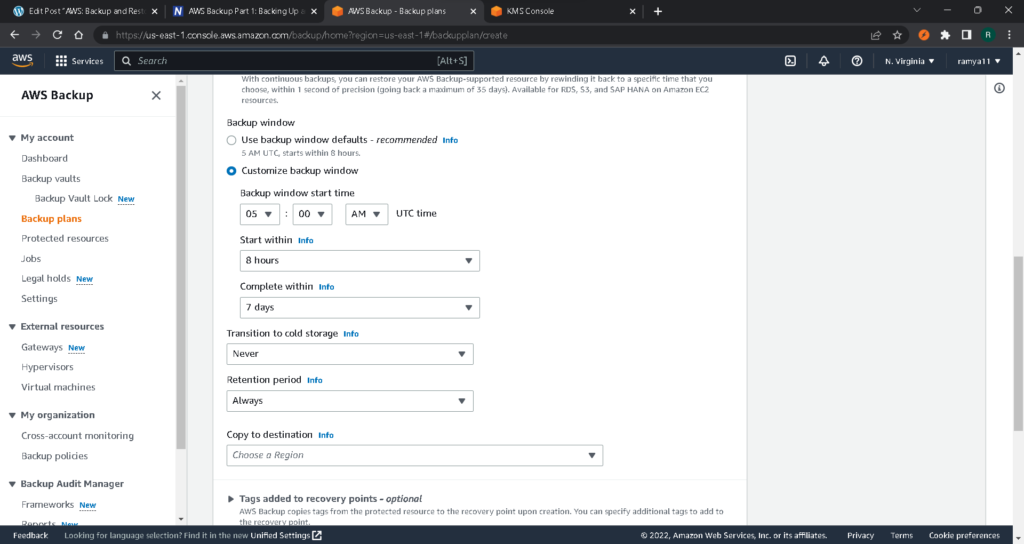
After you have defined the life cycle, pick a desired backup vault. We chose the one we created earlier.
Next, specify the tags that will be added to your recovery points and the tags you want to use for the backup plan itself. Again, this step helps with visibility when organizing files.
Finally, after you have configured everything, click on “Create plan.”
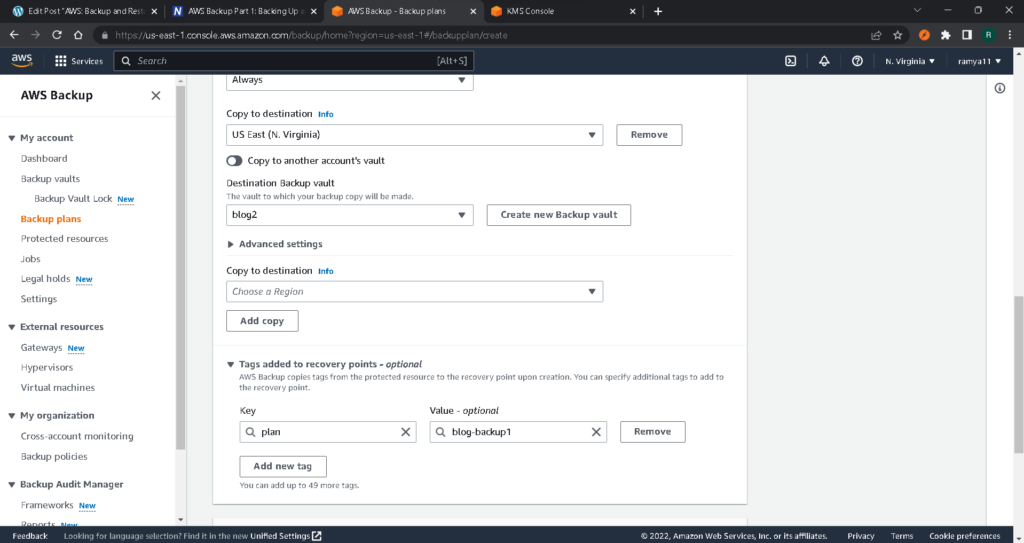
Your new backup plan is now ready.
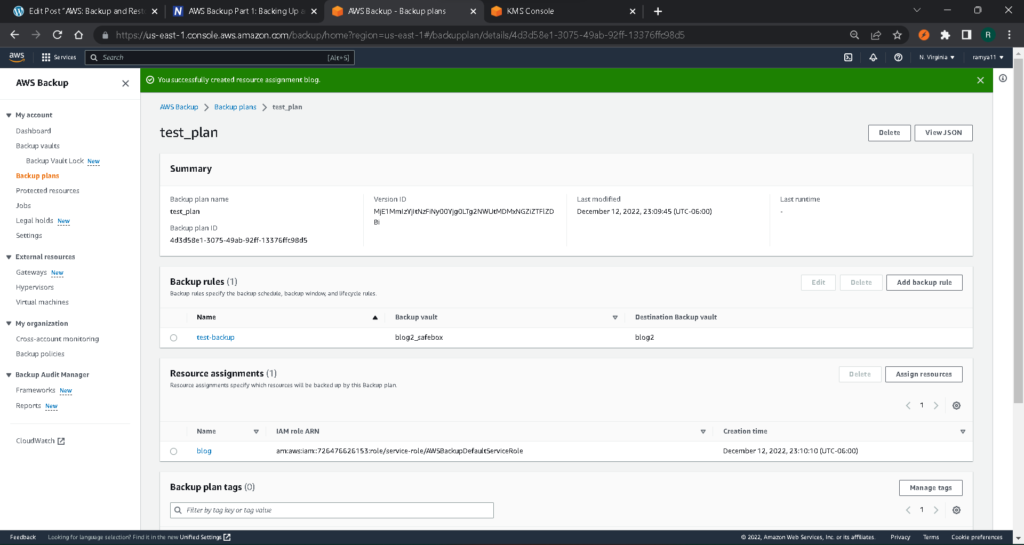
If you click on your backup rule, you can see a summary of it, showing the details of your current configuration.
Backup Plan Option 2: “Start from an Existing Plan”
You can create a backup plan from an existing one. This option gives you a premade configuration which you can modify if needed. For example, you can opt for a simple daily backup with a 35-day retention period. You can also employ a more complex plan by selecting the last option under the “Choose plan” drag down menu—daily, weekly, and monthly backups, with a 7-year retention.
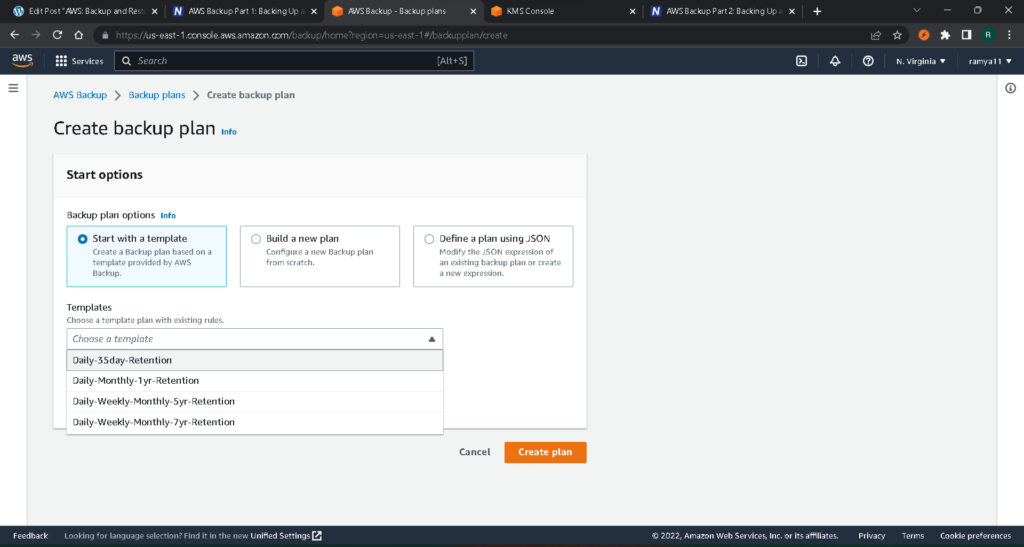
A plan like this will create the GFS rotation described earlier. In the screenshot below, you can see the three distinct backup rules contained within this plan.
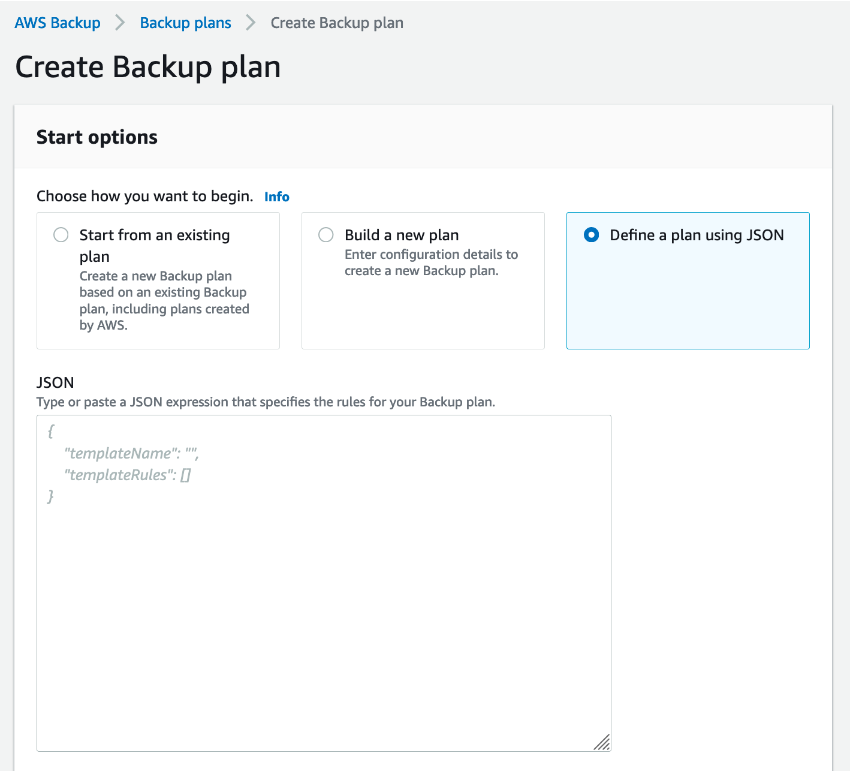
Building a Backup Plan Option 3: “Define a Plan Using JSON”
The last option is to define a plan using JSON (JavaScript Object Notation). This can be especially useful when you are looking to share backup plan configurations with multiple AWS accounts. An alternative way to share backup configurations is by using a basic, consistent template for your plans and modifying it slightly for each use case.
Assigning Resources to Your Backup Plan
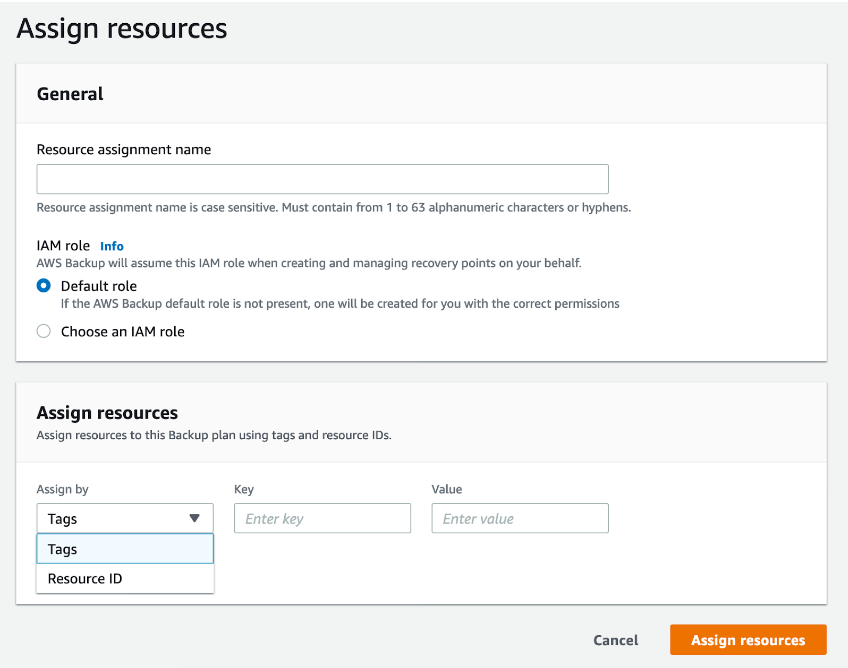
After you have created a backup plan, you need to assign the resources that will be backed up. Within your backup plan, open “Assign resources.”
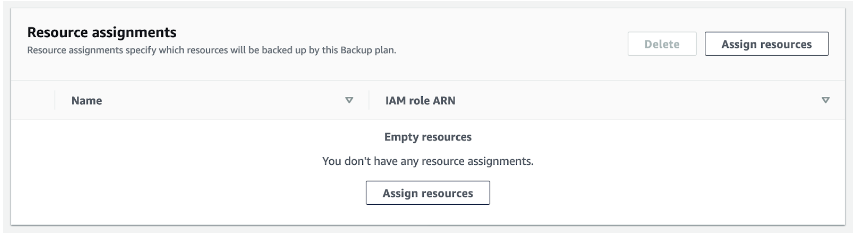
Add a name for your resource assignment. You can leave the default role as IAM.
Resource assignment can be done in two different ways. You can assign resources using IDs, or you can use tags to collect multiple resources at the same time. Assigning individual resources through IDs works when you don’t have many of them or when you want to do a quick backup. It can be somewhat impractical, though, since you need to know your resource ID. If you don’t, you have to go back to your console to find it. Adding resources via tags is a great way to create logical groupings, making it preferable for larger environments. You can use tags to design a complete backup strategy.
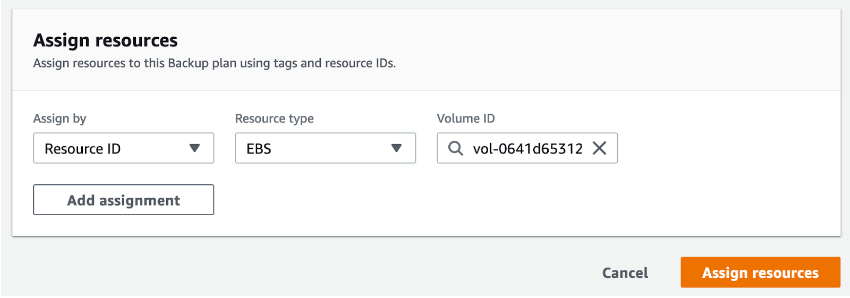
For our example, we will choose a single resource (EBS volume) using its ID and confirm it by clicking “Assign resources.”
Backing Up Resources
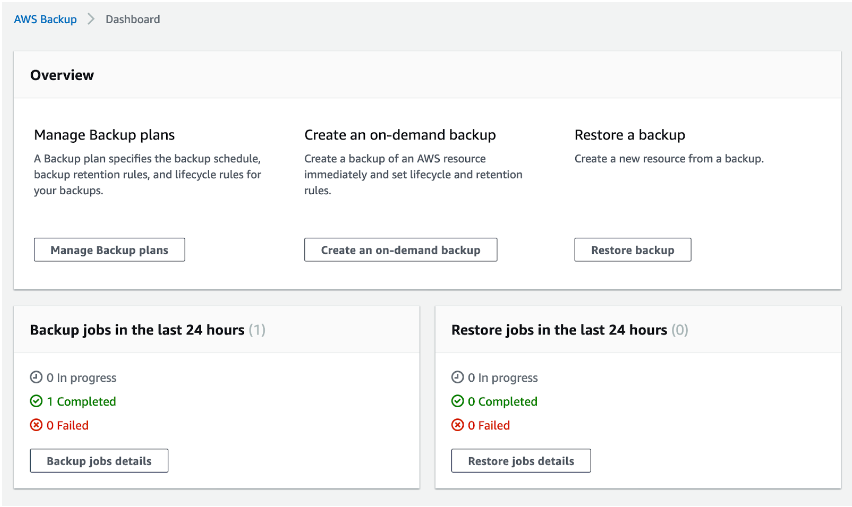
This completes the setup process; now, all you need to do is wait for your backup job to start. When it does, you will be able to see that the job is in progress by looking at the console.
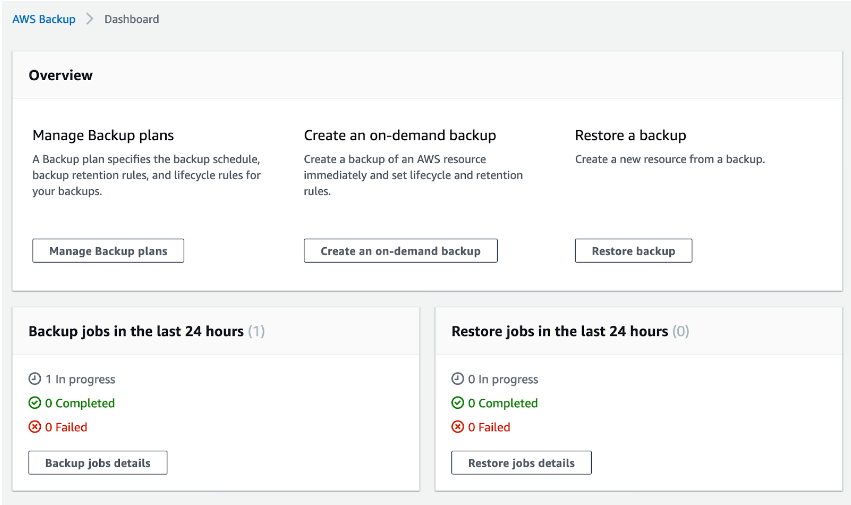
You can also open your “Jobs” tab and look at the details there.
When the backup is complete (or has failed), the dashboard will be updated.
AWS Backup Logs
As with other AWS services, you can keep track of your API calls in AWS Backup using AWS CloudTrail. Amazon CloudTrail provides records of all AWS Backup actions taken by a user or another service. Records show which action was taken, a timestamp for that action, and the IP address of the originating request, among other details. For more information on setting up logging for AWS Backup using AWS CloudTrail, please consult Amazon’s documentation.
Restoring Your Resources Using the AWS Web UI: A Step-By-Step Guide
Let’s pick up where we left off in the previous article. Open the AWS Backup dashboard. There, you’ll have the option to restore the backups that have been made.
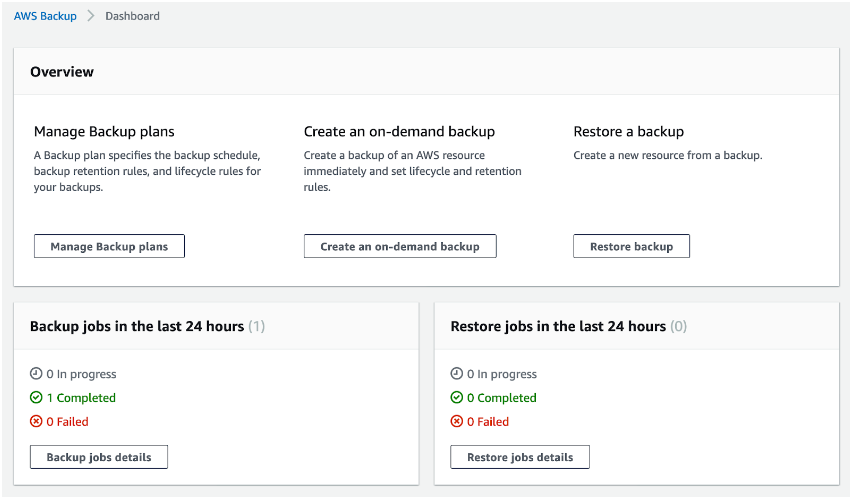
At the moment, we only have one resource configured for backups—our EBS volume.
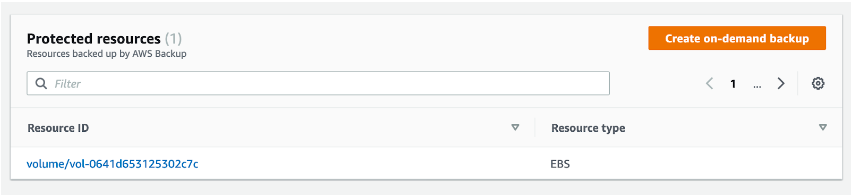
If we open the resource, we can see that two backups have been completed over the past two days. In this example, we’re going to restore the first backup that was made. Choose the older recovery point, and click on “Restore.
Several options exist here. First, since we backed up an EBS volume, we can either restore it as an EBS volume or as a Storage Gateway volume. The latter option can be very useful in Disaster Recovery (DR) scenarios. Next, you can choose the volume type that it will be restored as. Even if you backed up a General Purpose (gp2) volume, at this point, you have the option to switch it to a Provisioned IOPS (io1) volume or any other type of volume. Because you also pick the desired volume size here, you can increase volume capacity at this step and prevent the need to modify the volume later. You can also choose your Availability Zone (AZ) here, something worth doing if you are using specific AZs in your business environment.
Finally, you can specify an IAM role that AWS Backup will assume. You can use the default here.
When you are done with the configuration, click on “Restore backup.”
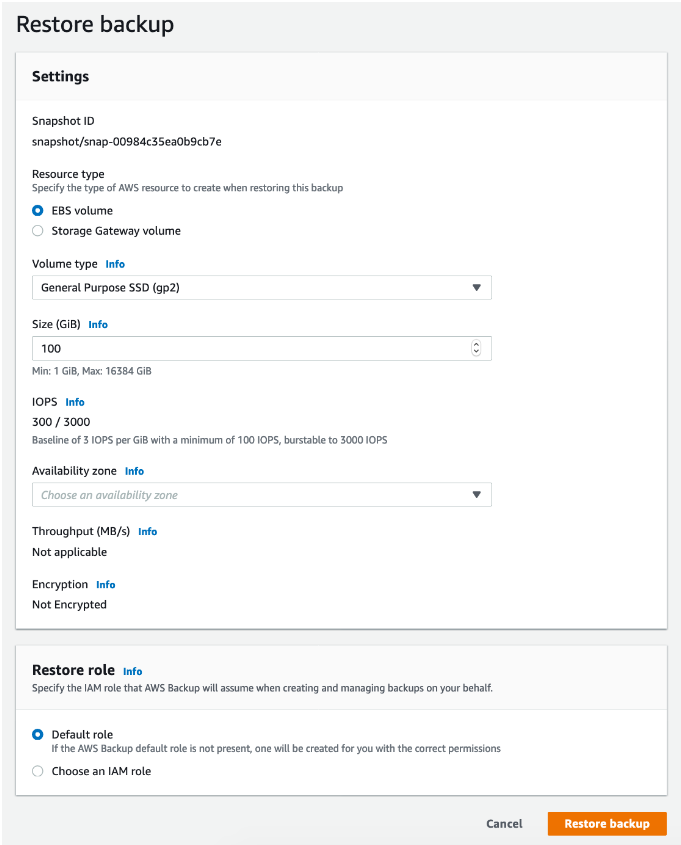
The restoration process will now begin. You can watch its progress under the “Jobs” tab. The process of restoring a volume usually takes a couple of minutes.
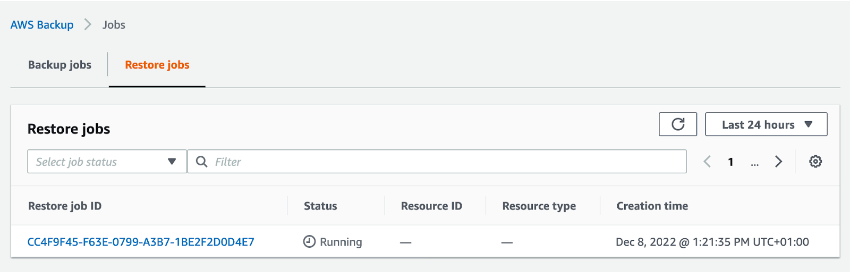
When restoration is complete, the status shown on the screen will change, and your new resource ID will appear.
You can find the new volume using its ID. As you can see in the screenshot above, the volume is available for use.

Backing Up Your Resources Using the AWS CLI: A Step-By-Step Guide
Whether you can’t access the AWS web UI or you simply want to introduce automation into various processes, knowing how to use the AWS CLI to backup and restore resources is very handy. It’s a bit less intuitive than working with the web UI, but, since the AWS CLI is a powerful tool for DevOps engineers, it’s worth learning how to use it. Additionally, some features, like adding notifications for the vault, are only available through the CLI.
Preparing the AWS CLI for Use
Using the AWS CLI requires some basic preparation. You need to set up permissions, which will vary depending on where you are going to use the tool. If you use it from your local computer, you need to generate AWS keys (an access key ID and a secret access key that you will add to the configuration). If you use an AWS instance to run the AWS CLI, you will need to attach an IAM role with necessary privileges to the instance. For security purposes, roles are always a safer option, as keys can get lost and end up in the wrong hands.
All of the commands that we will be using can be found in the backup section of the AWS CLI documentation.
Creating a Backup Vault
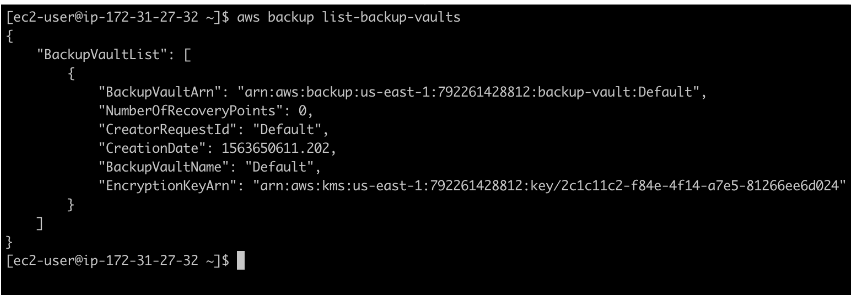
Before we create a backup vault, we need to determine which vaults are available. The command aws backup list-backup-vaults does that.
In the screenshot below, you can see that, at the moment, only the default vault exists.
To create a backup vault, one which we’re going to call “strongbox,” issue the following command: aws backup create-backup-vault –backup-vault-name strongbox.
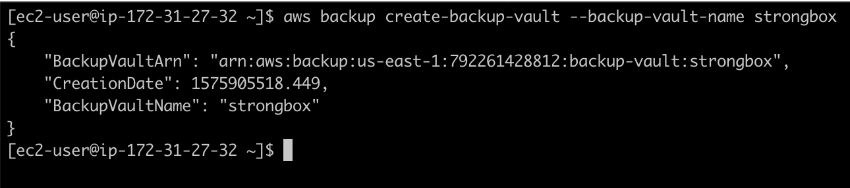
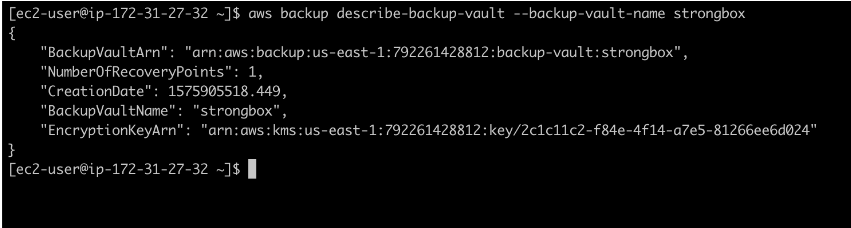
We can now describe our newly created vault with aws backup describe-backup-vault –backup-vault-name strongbox. Because it is empty right now, there are few details.
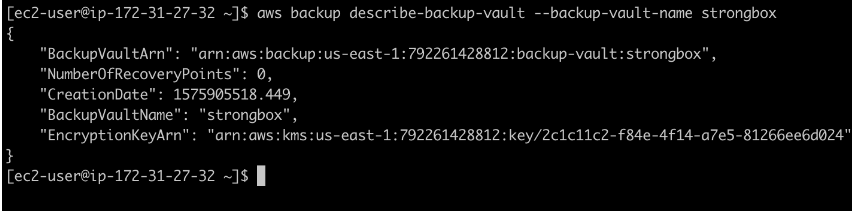
Now that the vault is ready, your final step is setting up notifications for the vault. We can add a desired SNS topic to be used each time a specific event occurs. The supported events are:
- BACKUP_JOB_STARTED
- BACKUP_JOB_COMPLETED
- RESTORE_JOB_STARTED
- RESTORE_JOB_COMPLETED
- RECOVERY_POINT_MODIFIED
- BACKUP_PLAN_CREATED
- BACKUP_PLAN_MODIFIED
These events are very useful for tracking AWS Backup processes, especially when you want to ensure that backup jobs have been successfully completed.
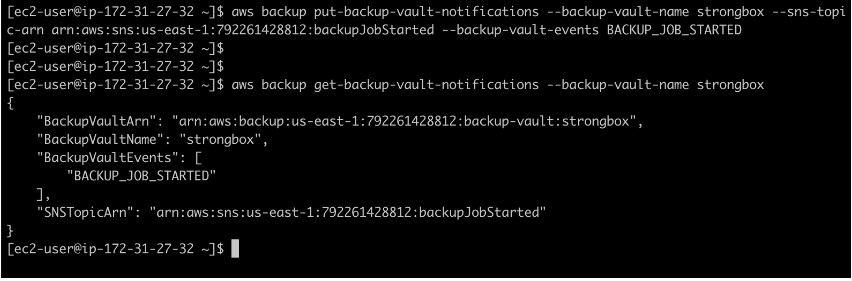
An SNS topic has already been created, so let’s create an event notification that occurs each time a backup job has been started. The command used to do that is aws backup put-backup-vault-notifications –backup-vault-name strongbox –sns-topic-arn yourSNSArn –backup-vault-events BACKUP_JOB_STARTED.
Creating a Backup Plan
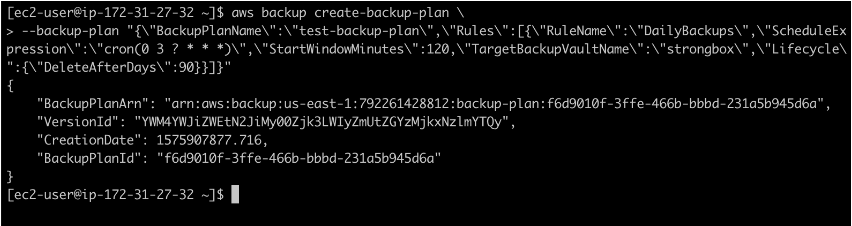
With a new vault and notifications in place, it’s time to create a backup plan. The command below will create a backup plan named “test-backup-plan,” along with a backup rule, “Daily Backups,” which schedules the process to start each day at 3AM with a 2-hour window. The data retention field is already set to delete backups after 90 days.
aws backup create-backup-plan --backup-plan “{\”BackupPlanName\”:\”test-backup-plan\”,\”Rules\”:[{\”RuleName\”:\”DailyBackups\”,\”ScheduleExpression\”,\”cron(0 3 ? * * *)\”,\”StartWindowMinutes\”:120,\”TargetBackupVaultName\”:\”strongbox\”,\”Lifecycle\”:{\”DeleteAfterDays\”:90}}]}”
You should modify these configurations to fit your business needs.
After the backup plan has been created, describe it using its ID with the command aws backup get-backup-plan –backup-plan-id youBackupPlanID. This will show you all the details that have previously been set.
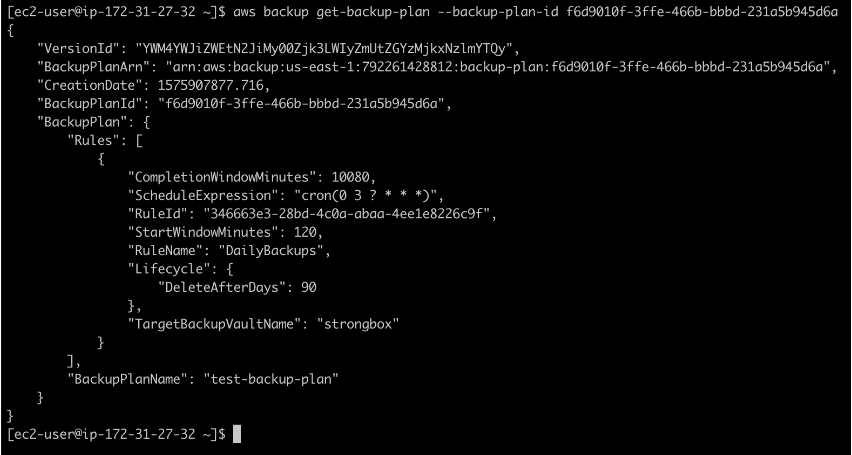
Assigning Resources to Your Backup Plan
Just as you did when configuring settings with the web UI, you will need to assign resources to the backup plan. The command aws backup create-backup-selection –backup-plan-id yourBackupPlanID –backup-selection SelectionName=test-assignment,IAMRoleArn=yourRoleARN,Resources=yourResourceARN will add this volume, as well as the default backup role, to the existing backup plan. Note that the default role name is “AWSBackupDefaultServiceRole.” In your case, the account number will be different. Of course, you can create your own role instead of using the default one.
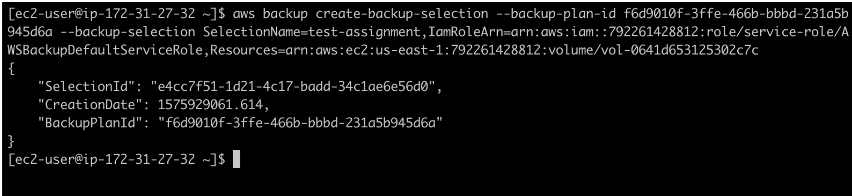
Now, all you need to do is wait for the backup window to appear and then monitor the progress of the backup. If you added the same SNS event notification that we did, you will get an email (or have a message sent to the SQS queue, creating a more complex pipeline) as soon as the backup has started.
When the backup is complete, you can use the command aws backup describe-backup-vault –backup-vault-name strongbox to see that the newly created vault has a recovery point.
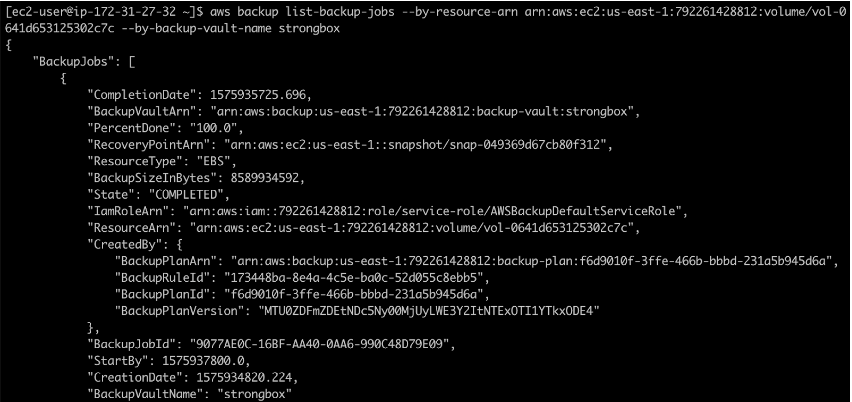
At this point, you can list all backup jobs if you have multiple use parsing by resource-arn. You’ll want to look for a Recovery Point ARN, which you will need to use to restore the data later on.
The command that enables you to do this is aws backup list-backup-jobs –by-resources-arn yourResourceARN –by-backup-vault-name strongbox.
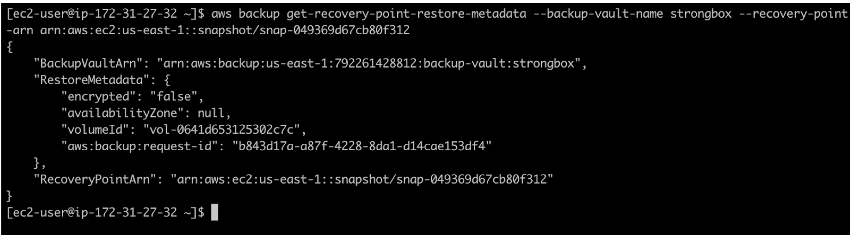
You can also get the restore point metadata, which might contain some important information. You can find out whether or not encryption has been used, which Availability Zone the data was stored in (in our example, none is set; but, since us-east-1c is where our EC2 instance that uses the volume resides, this is the AZ that will hold the restoration), and volume ID. To get the metadata, use the command aws backup get-recovery-point-restore-metadata –backup-vault-name strongbox –recovery-point-arn yourRecoveryPointARN.
Restoring Your Resources Using the AWS CLI: A Step-By-Step Guide
With the AWS CLI, you initiate a restore job by using the command aws backup start-restore-job –recovery-point-arn yourRecoveryPointARN –metadata encrypted=false,availabilityZone=us-east-1c,volumeId=yourVolumeID –iam-role-arn yourIAMRoleARN.

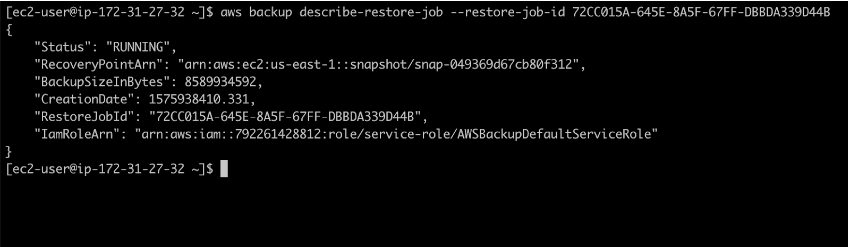
The command aws backup describe-restore-job –restore-job-id yourRestoreJobID will allow you to look at the details of the job being run, including its status (in this case, currently still running).
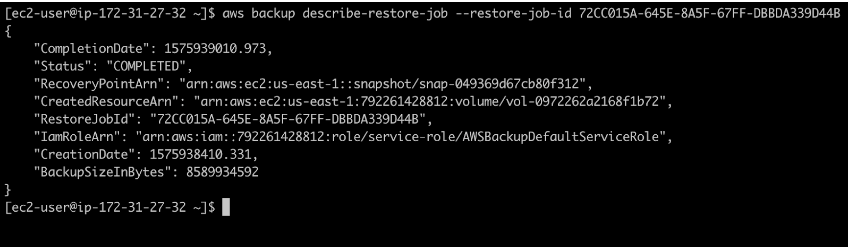
After the restore is done, the status will change to “completed,” and you will also notice a newly created resource with its resource ARN. In our case, that resource is a restored EBS volume that is now ready to be used.
Summary
The two parts of this article provided detailed how-to guides for backing up and restoring resources with AWS Backup—first, using the AWS web UI, and then using the AWS CLI. While the web UI method is more commonly employed (and is somewhat easier to use), the AWS CLI has its benefits and will often be useful to those skilled at operating within AWS.