Amazon Neptune, it is a graph-based database service from Amazon. This system made it easy to build and run applications that work with highly connected datasets. The core of Neptune is a purpose-built, high-performance graph database engine. This engine is optimized for storing billions of relationships and querying the graph with milliseconds latency. This majorly based on graphs concept which involves nodes, edges and their properties. Neptune supports the popular graph query languages Apache TinkerPop Gremlin, the W3C’s SPARQL, and Neo4j’s openCypher, this wide range support enables you to build queries that efficiently navigate through highly connected datasets.
Neptune is highly available, with read replicas, point-in-time recovery, continuous backup to Amazon S3, and replication across Availability Zones. Neptune provides data security features, with support for encryption at rest and in transit. Neptune is fully managed, so you no longer need to worry about database management tasks like hardware provisioning, software patching, setup, configuration, or backups.
Amazon Neptune has a great documentation to get started with graph-based database system, if you are new to Neptune, or even new to graph representation.
Key Service Components
- Primary DB instance – Supports read and write operations and performs all of the data modifications to the cluster volume. Each Neptune DB cluster has one primary DB instance that is responsible for writing (that is, loading or modifying) graph database contents.
- Neptune replica – Connects to the same storage volume as the primary DB instance and supports only read operations. Each Neptune DB cluster can have up to 15 Neptune Replicas in addition to the primary DB instance. This provides high availability by locating Neptune Replicas in separate Availability Zones and distribution load from reading clients.
- Cluster volume – Neptune data is stored in the cluster volume, which is designed for reliability and high availability. A cluster volume consists of copies of the data across multiple Availability Zones in a single AWS Region. Because your data is automatically replicated across Availability Zones, it is highly durable, and there is little possibility of data loss.
Features of Amazon Neptune
- Serverless option – Neptune serverless is an on-demand option, it automatically adjusts database capacity based on application’s need. It can scale the graph database workloads instantly to hundreds and thousands of queries.
- High throughput, low latency for graph queries – Neptune efficiently stores and navigates graph data, and uses a scale-up, in-memory optimized architecture to allow for fast query evaluation over large graphs.
- Easy scaling of database compute resources – you can easily scale the compute and memory resources powering your production cluster up or down by creating new replica instances of the desired size, or by removing instances.
- Instance monitoring and repair – The health of your Neptune database and its underlying EC2 instance is continually monitored. If the instance powering your database fails, the database and associated processes are automatically restarted. Neptune recovery does not require the potentially lengthy replay of database redo logs.
- Fault-tolerant and self-healing storage – Each 10 GB chunk of your database volume is replicated six ways across three Availability Zones. Neptune uses fault-tolerant storage that transparently handles the loss of up to two copies of data without affecting database write availability and up to three copies without affecting read availability. Neptune storage is also self-healing—data blocks and disks are continually scanned for errors and replaced automatically.
- Automatic, continuous, incremental backups and point-in-time restore – Neptune’s backup capability enables point-in-time recovery for your instance. This allows you to restore your database to any second during your retention period, up until the last five minutes.
- Database snapshots – Database snapshots are user-initiated backups of your instance stored in Amazon S3 that will be kept until you explicitly delete them. They use the automated incremental snapshots to reduce the time and storage required. You can create a new instance from a database snapshot whenever you desire.
- Supports openCypher v9 for property graph – Neptune supports building graph applications using openCypher, currently one of the most popular query languages for developers working with graph databases. Business and research personals and organizations are pleased with openCypher’s SQL-inspired syntax because it provides a familiar structure to compose queries for graph applications.
- Network Isolation – Neptune runs in Amazon VPC, which allows you to isolate your database in your own virtual network and connect to your on-premises IT infrastructure using industry-standard encrypted IPsec VPNs. In addition, using the Neptune VPC configuration, you can configure firewall settings and control network access to your database instances.
- Encryption – Neptune supports encryption in transit with TLS version 1.2. Neptune allows you to encrypt your databases using keys you create and control through AWS Key Management Service (KMS). On a database instance running with Neptune encryption, data stored at rest in the underlying storage is encrypted, as are the automated backups, snapshots, and replicas in the same cluster.
- Advanced auditing – Amazon Neptune allows you to log database events with minimal impact on database performance. Logs can later be analyzed for database management, security, governance, regulatory compliance and other purposes. You can also monitor activity by sending audit logs to Amazon CloudWatch.
- Easier to operate – Neptune makes it easier to operate a high performance graph database. With Neptune, you do not need to create custom indexes over your graph data. Neptune provides timeout and memory usage limitations to reduce the impact of queries that consume too many resources.
- Automatic software patching – Neptune will keep your database up-to-date with the latest patches. You can control if and when your instance is patched through Database Engine Version Management.
- Database event notifications – Neptune can notify you through email or SMS of important database events like automated failover. You can use the AWS Management Console to subscribe to different database events associated with your Amazon Neptune databases.
- You can clone a Neptune database with just a few steps in the AWS Management Console, without impacting the production environment. The clone is distributed and replicated across three Availability Zones.
- Property graph bulk loading – Neptune supports fast, parallel bulk loading for Property Graph data that is stored in S3. You can use a REST interface to specify the S3 location for the data. It uses a CSV delimited format to load data into the Nodes and Edges. See the Neptune Property Graph bulk loading documentation for more details.
- Pay only for what you use – There is no up-front commitment with Neptune; you pay an hourly charge for each instance that you launch, or the database resources you consume for serverless. When you’re finished with a Neptune database instance, you can delete it. You do not need to overprovision storage as a safety margin, and you only pay for the storage you actually consume.
Neptune Limitations
Though Neptune has good working for graph databases, it would be unwise not to list out its limitations. These might not be disadvantages, but few points to consider before starting a service. It has got few limitations in terms of its location availability and storage spaces. Example, Maximum storage for Neptune cluster is limited to 128 tebibytes (TiB), and further in some countries like China it’s further limited to 64 tebibytes.
There’s another limitation considering the size of individual property label. Each property label is restricted to 55MB in size, which means quad (S, P, O, G) of an RFD quad cannot exceed the limit of 55 MB. If there is a need of such larger objects, it is advised to store the file in Amazon S3 buckets and import the path as a property or label.
If you want to learn more about the limitations, click here.
Amazon Neptune Pricing
Amazon is one of the best service providers with pay-as-you-go tariff. The prices for Neptune start from as low as $0.093 per hour and could go as high as $19.0903 per hour based on the instance that you’d choose to meet your needs and requirements. You can follow this link to look at price charts.
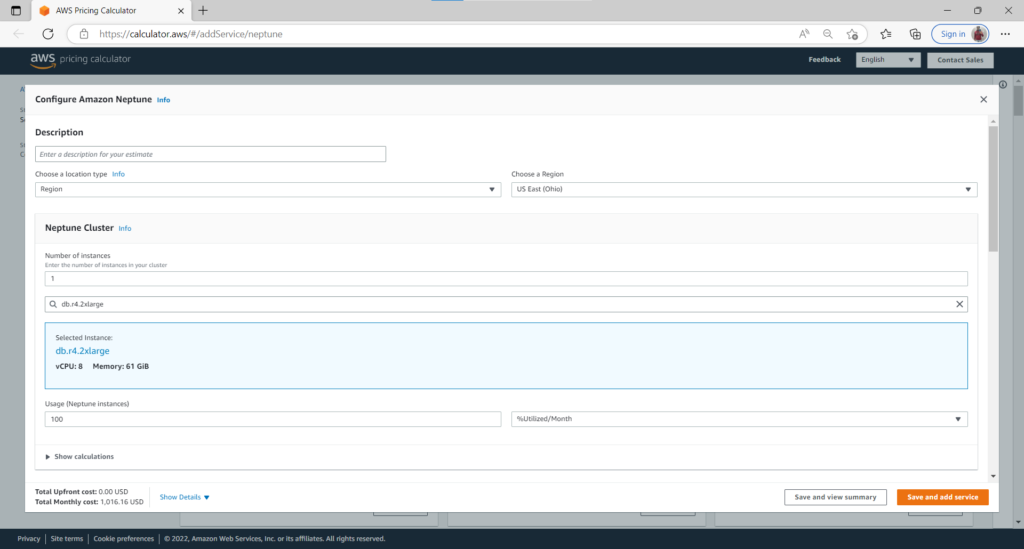
In the price calculator, configure your settings and inputs to get a price quote.