Do you have an API that is called regularly? AWS Lambda functions have the ability to call an API on a regular schedule. What if you need to store the data behind that API too? Well, Lambda can also help store your data in s3 for the long term.
Using an AWS EventBridge trigger, we’ll be able to put together a Lambda function that automatically calls an API at regular intervals of time. Then, the data from the API can be stored uniquely within an s3 bucket to be used at a later date for a wide variety of uses.
Setting Up an s3 Bucket
In order to test the function, we’ll want to set up a new s3 bucket first. If there is an existing s3 bucket available to use, feel free to skip this section.
For our purposes, setting up an s3 bucket is going to be pretty simple. After logging into your AWS Management Console, use the search bar to search s3. Then, click on the first offering s3.
In the s3 Console, select the Create Bucket button, which will land on a Create Bucket interface.
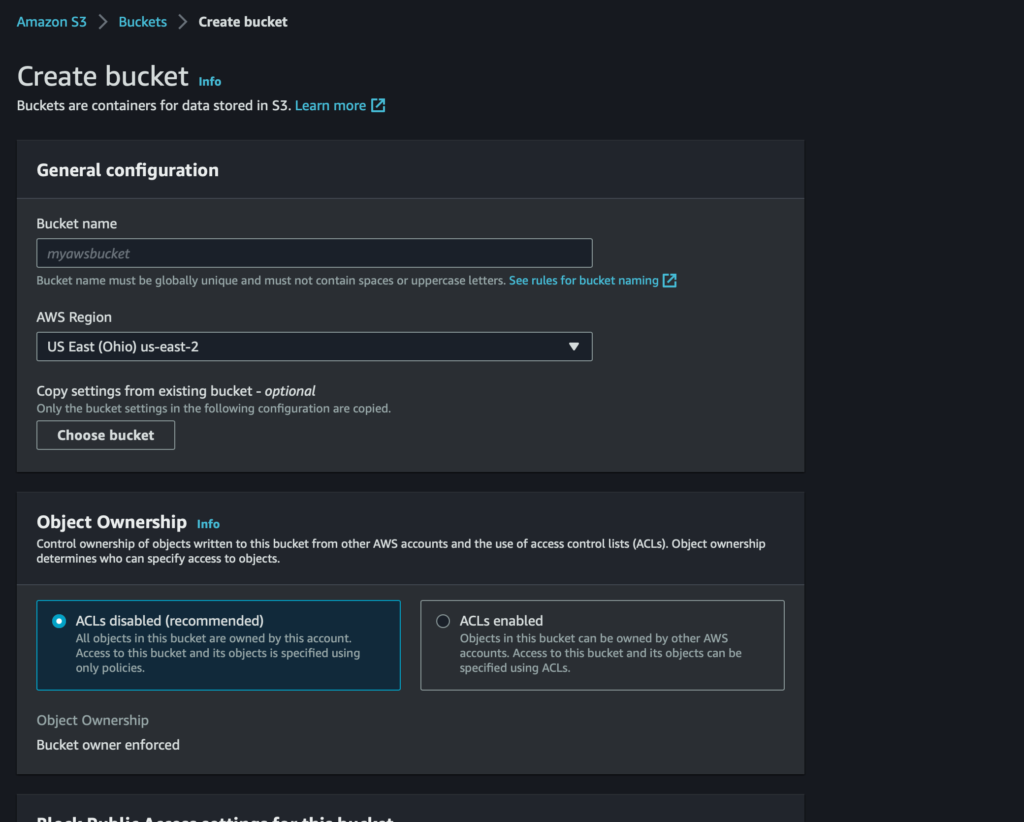
On the Create Bucket page, fill out the following items:
Bucket Name, be sure to follow the naming guideline hereAWS Region
Finally, scroll down and select Create Bucket. For now, this is all we will need to do related to the s3 bucket. However, keep the name of the bucket handy!
Setting Up the Lambda Function
For simplicity, this Lambda function will be put together using the AWS Lambda console. The Lambda console makes it really easy to follow along and set up the function the right way the first time.
The first step for setting up the Lambda function is to create the Lambda Function. In the AWS Management Console enter Lambda the search bar and select the first service that appears. This leads you to the Lambda console.
While in the Lambda console, select the button that says Create Function. From there you will be led to a Create Function form. We will author our own function, so leave that selection at the top of the page alone. You will need to fill out the following information:
Function Name, for example,my_scheduled_lambda_functionRuntime, select the Python 3.9 runtime
The Permissions section can be left as is for now. The permissions will need to be altered later, but we’ll do this through other means. Now you can click the Create Function button
Setting Up the Function Trigger
Now you should see a page with a large diagram, something like the image below:
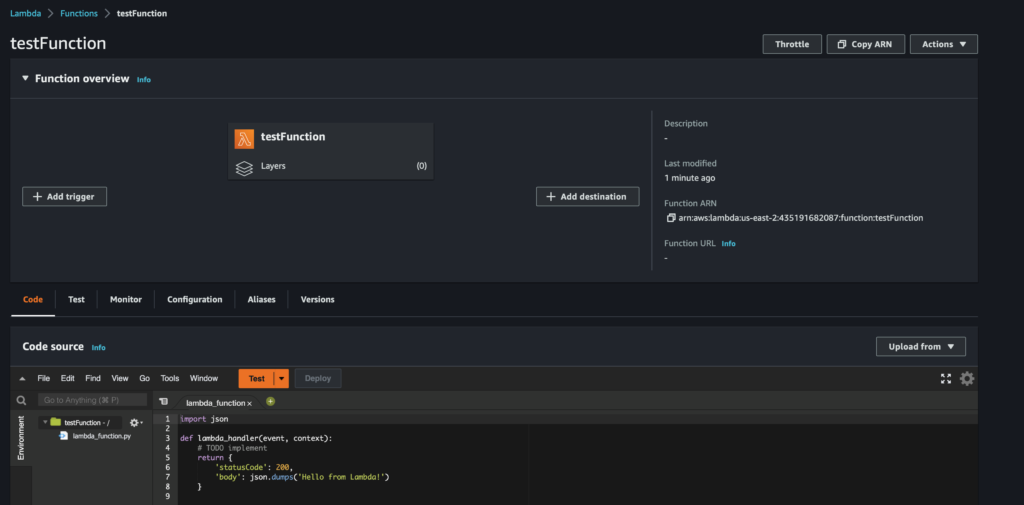
First, we are going to look at the Add trigger selection on the lower left portion of the diagram. This is how we will set up a trigger that will invoke our function on a regular schedule. Triggers are the term AWS uses to describe resources that invoke the Lambda function. Read more about Triggers
On the Add Trigger page, we’ll need to select an AWS resource to act as a trigger. For this tutorial, the resource is Event Bridge (also known as CloudWatch Events). The EventBridge trigger gives users the ability to define events that drive when a function will be invoked. Read more about EventBridge
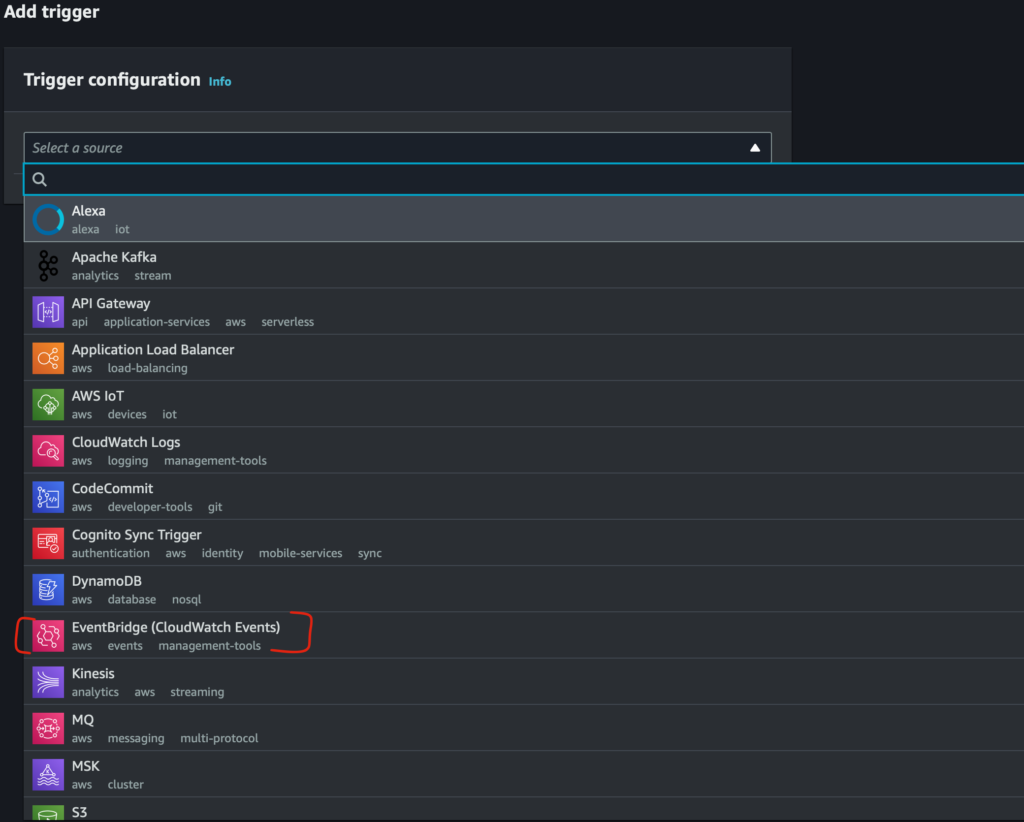
We need to create a new event rule, so select the indicator for Create a new rule. This will bring up a form, which will require the following fields to be filled out:
Rule Name, for example,invoke_function_every_X_timeRule Type, selectSchedule Expression
The AWS Schedule expressions are a little tricky. If your function will need to run regularly, say every minute, or 10 minutes, then use the rate() syntax. If your function will need to run on a more complex schedule, say on the third of every month at 8 am, use the cron() syntax. The cron() syntax on AWS is a little different and has specific requirements, such as your function must either include the ? operator for days-of-week or days-of-month fields. Read more about Schedule Expressions
After creating your schedule expression, select the Add button at the bottom of the page.
Add the s3 Bucket Policy
We’ll need to wrap up the function configurations before we can really test our function. So, now we’ll return to setting up the s3 bucket permissions.
In order to add new files to the s3 bucket, we need to make sure the execution role for the Lambda function has PutObject permission for our s3 bucket. We’ll set this up in the AWS IAM console.
Use the search bar again and search for IAM and select the first offering that appears in the search results. Once one the IAM Management Console, look at the left sidebar, under Access Management and select Policies. We’ll create a new policy first, then attach it to our Lambda functions execution role.
Select Create Policy and then use the Visual Editor to fill out the following items:
Service, search fors3and select thes3optionActions, under the access level select theWritedrop-down and selectPutObjectunder thePermissions Managementdrop-down selectPutObjectAclResources, selectSpecificand then selectAdd ARN. Enter the name of the s3 bucket inBucket Name, for the bucket you want to use and selectAnyforObject Name
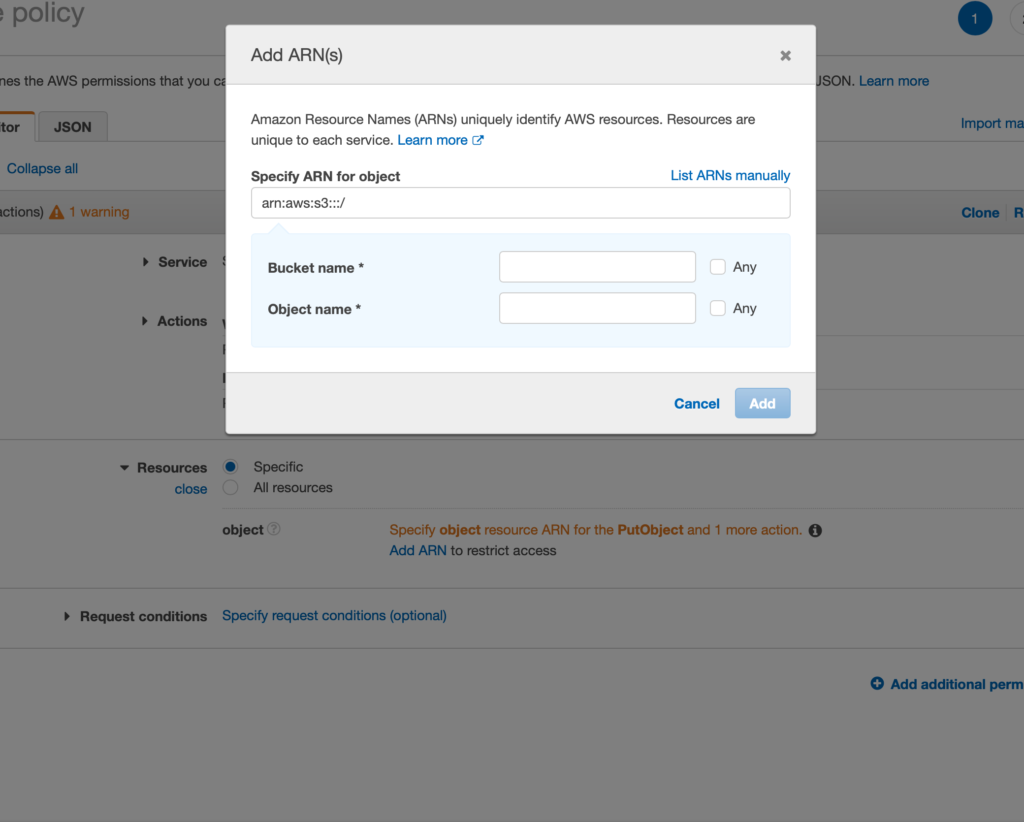
After filling out the Service, Action, and Resources sections of the visual editor, select Next:Tags button, and then finally Next: Review. On the Review page, enter an easy-to-remember name for your policy, then select Create Policy.
After creating a policy, we can find it again later from the list of policies found under Access Management > Policies. From this screen, look at the left sidebar again and select Roles under the Access Management drop-down.
In Roles, search for a role that contains the Lambda Function name from before. Once you’ve found the role, select it. Selecting the will navigate to a page that lists all policies attached to the selected role. On the right side of the screen select Add Permissions > Attach Policies. Selecting Attach Policies will navigate to the very same list of all policies available. Search for your recently created policy by name, select it, and then scroll to the bottom of the page and click Attach Policy. Now the Lambda function’s execution role is able to add new objects to the bucket we set up at the beginning of this tutorial.
Coding Up the Function
Now that the Lambda function is configured correctly, we can easily put together the code that will automatically add new objects, with our API’s data, to the s3 bucket.
For this tutorial, we’ll be using an API that returns a random fact about numbers. Click here to generate a random number fact for yourself
For each call to the API, we’ll want to have our final data structure look something like this:
{
"math_fact": "3641 is an hexagonal prism number.",
"time_fact_recieved": "2022-12-11 16:17:41.649271"
}
We will create a JSON file with two fields:
math_fact, the randomly generated fact from the APItime_fact_recieved, a timestamp indicating approximately when the math fact API was called
Both fields should be unique enough, for the purposes of this tutorial, that the facts being stored will not become redundant. Even if the number facts themselves are duplicated, there is likely still a way to filter them by the time_fact_recieved field in a unique way.
We will also want to have a way to distinguish each file within the s3 bucket while maintaining some kind of naming standard. One way this can be accomplished is with a UUID also known as a Universal Unique Identifier. We can create a unique, yet uniform file naming scheme which will make reading the data a little bit easier in the future, even if we decide to add a different type of data to the same bucket for any reason.
math_fact_0474ccc4-3c11-4e76-b8db-b9ebfb2dab42.json
To accomplish all of our goals we’ll use the following python libraries:
urllib3, make requests to the API, and parse the responsejson, work with JSON or JSON formatted stringsboto3, interact with AWS services in pythondatetime, create and interact with dates and timestampsuuid, create random UUIDs
The AWS Lambda console provides a small code editor that allows us to create our function in python and test it. The following code snippet will allow us to call the API, format our data, and put the JSON object in our specified s3 bucket.
import urllib3
import uuid
import datetime
import json
import boto3
def lambda_handler(event, context):
s3_client = boto3.client('s3')
http = urllib3.PoolManager()
# get api response
response = http.request('GET','http://numbersapi.com/random/math').data.decode('UTF-8')
# add a timestamp field
timestamp = str(datetime.datetime.now())
# combine both into a dictionary
fact_dict = {'math_fact':response,
'time_fact_received':timestamp}
# convert to json formatted string
fact_json = json.dumps(fact_dict)
# generate uuid for key name string
uuid_str = str(uuid.uuid4())
try:
s3_response = s3_client.put_object(Body=fact_json,
Bucket='test-article3-bucket',
Key='math_fact_{}.json'.format(uuid_str))
except Exception as e:
return "Error:\t{}".format(e)
return response
Resources
AWS Lambda documentation https://docs.aws.amazon.com/lambda/index.html
AWS s3 Bucket naming conventions https://docs.aws.amazon.com/AmazonS3/latest/userguide/bucketnamingrules.html
AWS EventBridge https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-what-is.html
python urllib3 https://urllib3.readthedocs.io/en/stable/
python JSON https://docs.python.org/3/library/json.html
python datetime https://docs.python.org/3/library/datetime.html
python boto3 https://boto3.amazonaws.com/v1/documentation/api/latest/guide/quickstart.html
python UUID https://docs.python.org/3/library/uuid.html
Numbers API http://numbersapi.com/#42