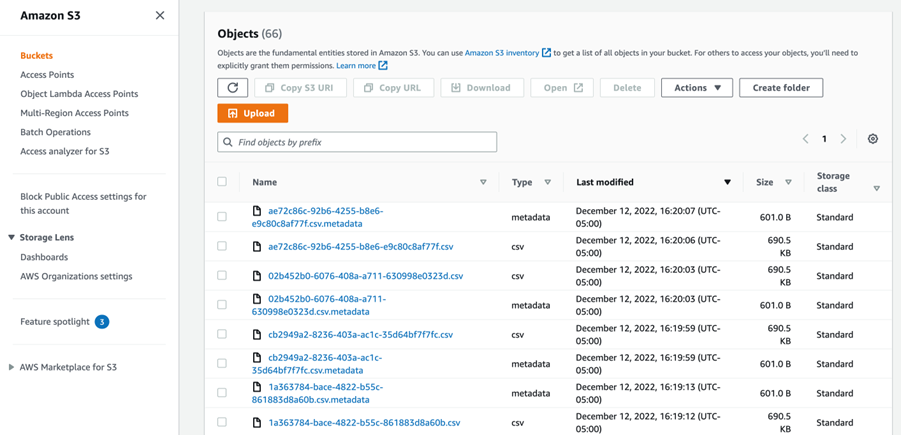
Here, we will be utilizing the Athena database and S3 buckets created as part of Connecting to the Athena Database using Python.
Now, we will discuss on how to schedule Athena queries using Amazon EventBridge, AWS Lambda, and Boto3 by AWS Python SDK.
AWS Lambda is a service that lets us run code without worrying about provisioning and managing any servers. Lambda runs our code on computing infrastructure and performs all the administration of resources such as servers and OS maintenance, capacity provisioning, auto-scaling, and logging. All one should do is just supply the code in the language lambda supports.
On the other hand, Amazon EventBridge is a serverless service that uses events to connect application components together, making it easier to build scalable event-driven applications.
Let’s discuss the process of scheduling Athena queries, the procedure has two main steps,
- creating a lambda function for Athena querying.
- creating a schedule using Amazon EventBridge to invoke the lambda function created in step 1 and perform the Athena query.
Note: We are going to use the code from Connecting to Athena Database using Python and modify it to fit the lambda function functionality and then invoke it using the EventBridge schedule to perform the querying and outputting the result to the output S3 bucket.
IAM Service Role:
During the creation of the lambda function and rule creation for scheduling in Amazon EventBridge, I let the services create new roles and assign the below policies for the two roles created to have proper permissions, to access Athena, S3, lambda, and scheduling. The policies are,
- AmazonAthenaFullAccess
- CloudWatchLogsFullAccess
- AWSQuicksightAthenaAccess
Note: Click here to learn how to assign policies to a role.
Lambda Function:
- Open the Lambda Console,
- Click on create function,
- Choose the “Author from scratch” option,
- Give a name to the function in the basic information tab,
- Choose runtime as Python 3.x available version,
In this demonstration, let the function create a new role and then click on “Create function”.
Since the function has been created we need to write the code in the function-code-section and chose the “Deploy” option.
Here is the screenshot of the lambda function I created “blog3_2”,
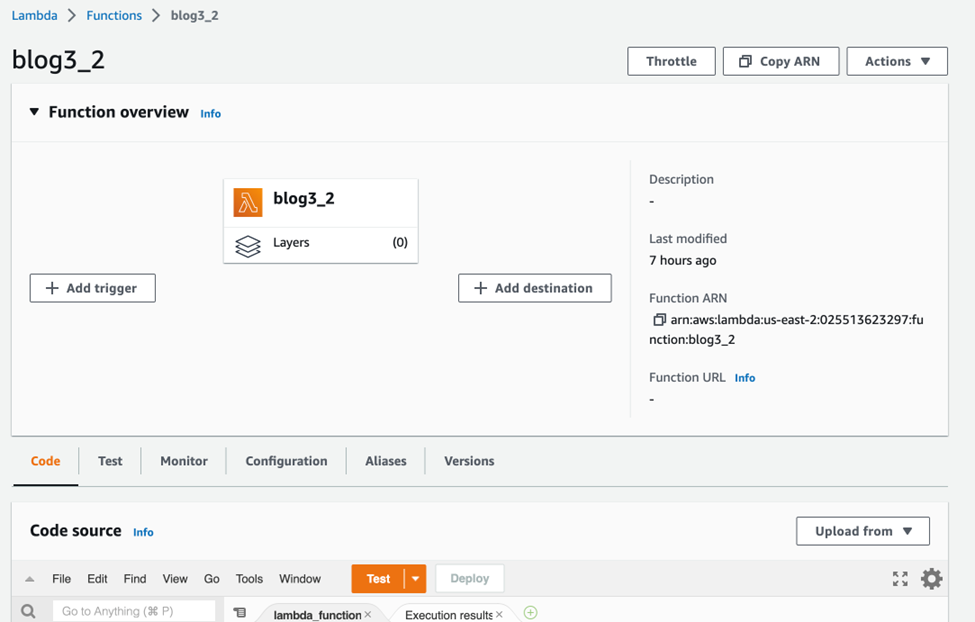
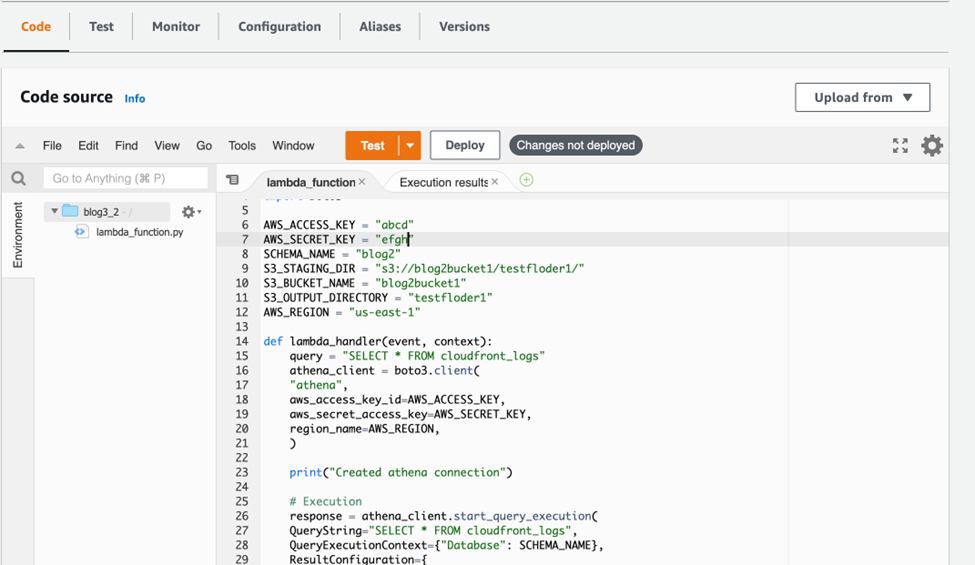
Note: Using dummy keys here, anyone who wishes to execute this code can use their own keys in the code.
- Lambda Function Code
import time
from typing import Dict
import boto3
AWS_ACCESS_KEY = "XXXXXXXXXXXXXXXXXXXXXXXX"
AWS_SECRET_KEY = "XXXXXXXXXXXXXXXXXXXXXXXXXX"
SCHEMA_NAME = "blog2"
S3_STAGING_DIR = "s3://blog2bucket1/testfloder1/"
S3_BUCKET_NAME = "blog2bucket1"
S3_OUTPUT_DIRECTORY = "testfloder1"
AWS_REGION = "us-east-1"
def lambda_handler(event, context):
query = "SELECT * FROM cloudfront_logs"
athena_client = boto3.client(
"athena",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION,
)
print("Created athena connection")
# Execution
response = athena_client.start_query_execution(
QueryString="SELECT * FROM cloudfront_logs",
QueryExecutionContext={"Database": SCHEMA_NAME},
ResultConfiguration={
"OutputLocation": S3_STAGING_DIR,
},
)
print("Hurrah")
while True:
try:
print("Hurrah3")
athena_client.get_query_results(
QueryExecutionId=response["QueryExecutionId"]
)
print("Hurrah4")
break
except Exception as err:
if "not yet finished" in str(err):
time.sleep(0.001)
else:
raise err
print("Hurrah5")
file_location: str = "query_results.csv"
s3_client = boto3.client(
"s3",
aws_access_key_id=AWS_ACCESS_KEY,
aws_secret_access_key=AWS_SECRET_KEY,
region_name=AWS_REGION,
)
s3_client.download_file(
S3_BUCKET_NAME,
f"{S3_OUTPUT_DIRECTORY}/{response['QueryExecutionId']}.csv",
file_location,
)
print("Hurrah2")
return response
return
We can test the function using a sample JSON input using “Test”.
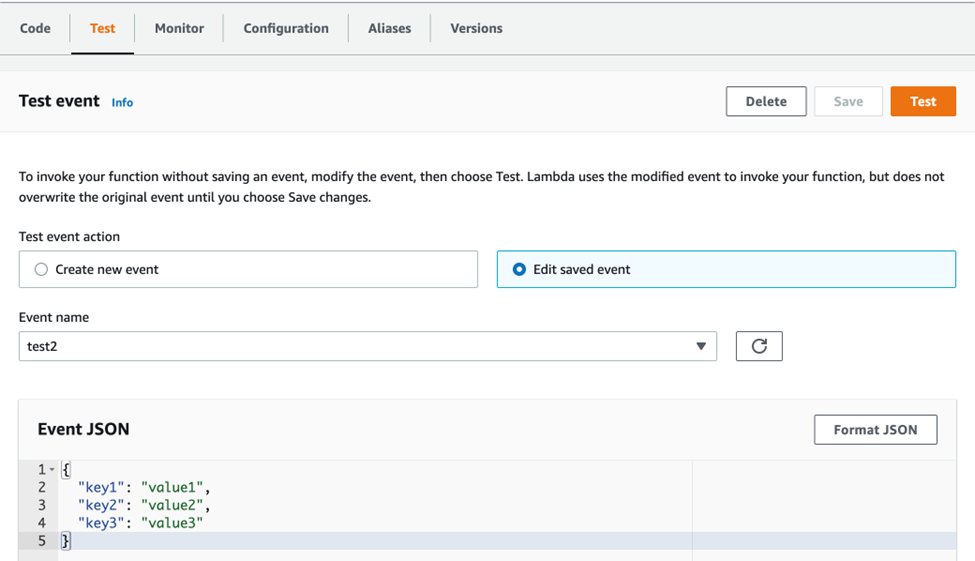
Note: Irrespective of the Test output, it is only used for invoking the lambda function, the test input itself doesn’t have any significance other than its usefulness to invoke the lambda function. The function performs its function and here the result can be seen in the S3 output bucket.
Remember from Connecting to Athena Database using Python that the code performs an Athena query to select all the items from the sample database and output it as a CSV file into the S3 output bucket.
- Creating a Schedule using Amazon EventBridge
Open the Amazon EventBridge console,
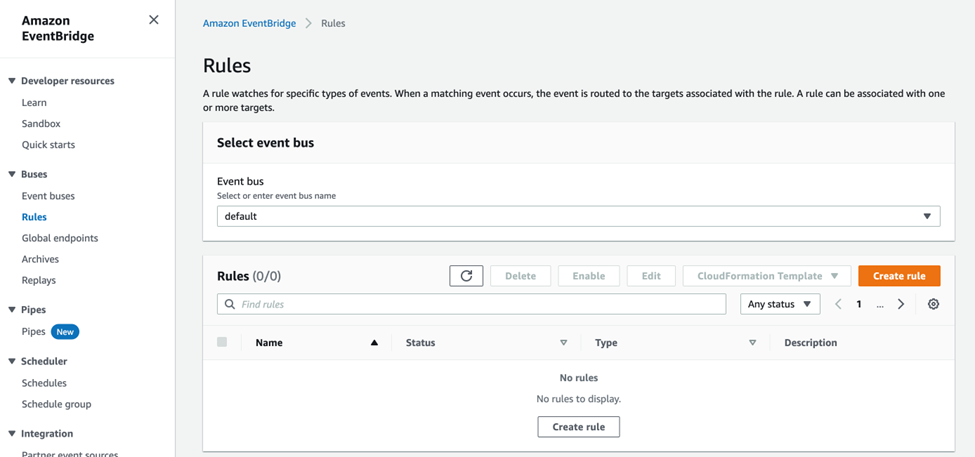
On the navigation pane, choose “Rules” and click on “Create rule”, give a name for the rule, and an optional description, and chose the default option for Event bus, for rule type chose “Schedule” and then click on “continue in EventBridge Scheduler”.
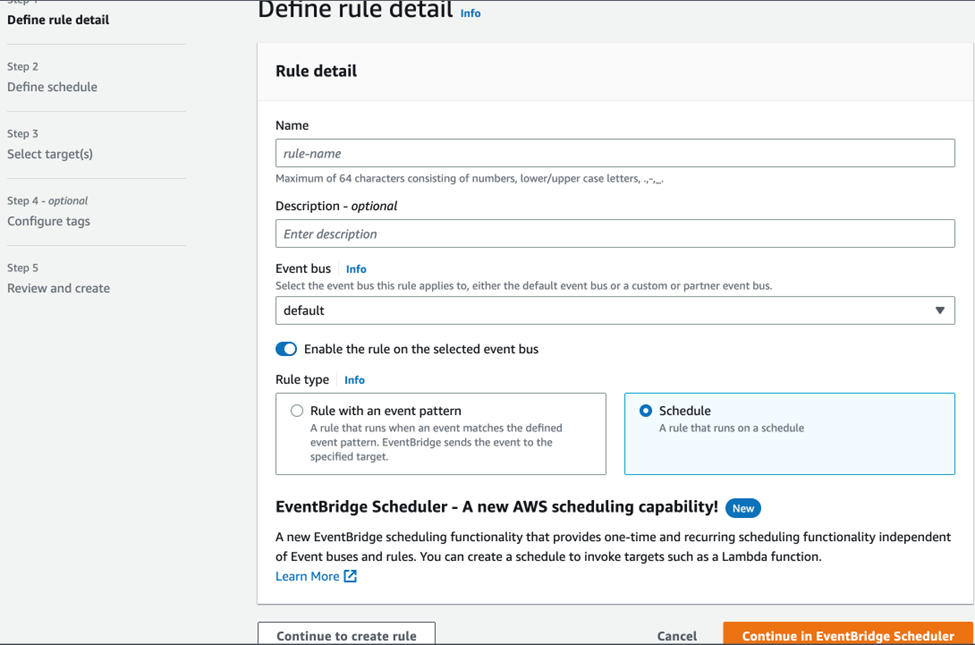
In the schedule pattern, choose the “Recurring schedule” and “Rate-based schedule” options and give the rate expression as every 1 minute.
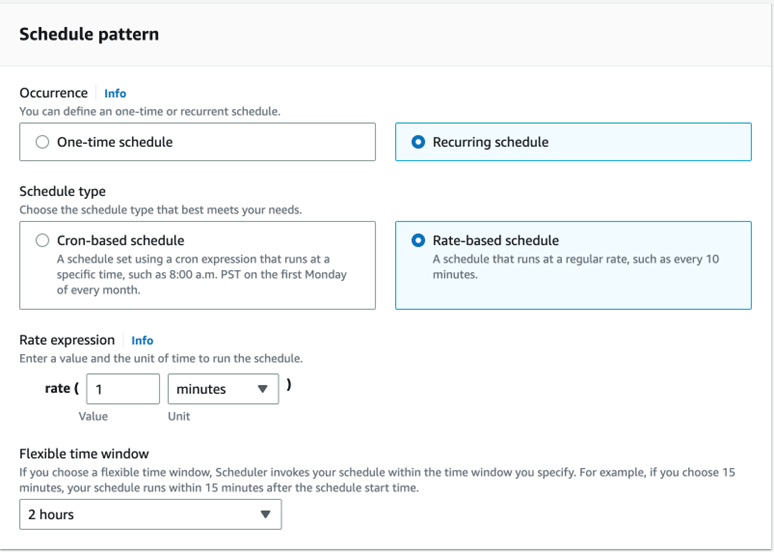
Now, choose the time frame at which the schedule must start and then click next,
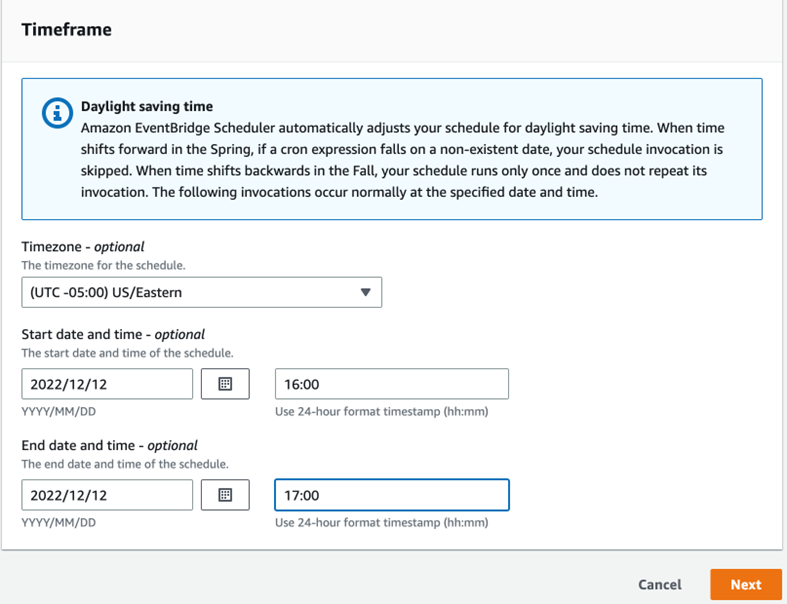
Now, in step 2, we need to select the target and here we will choose the lambda function to be invoked by the schedule,
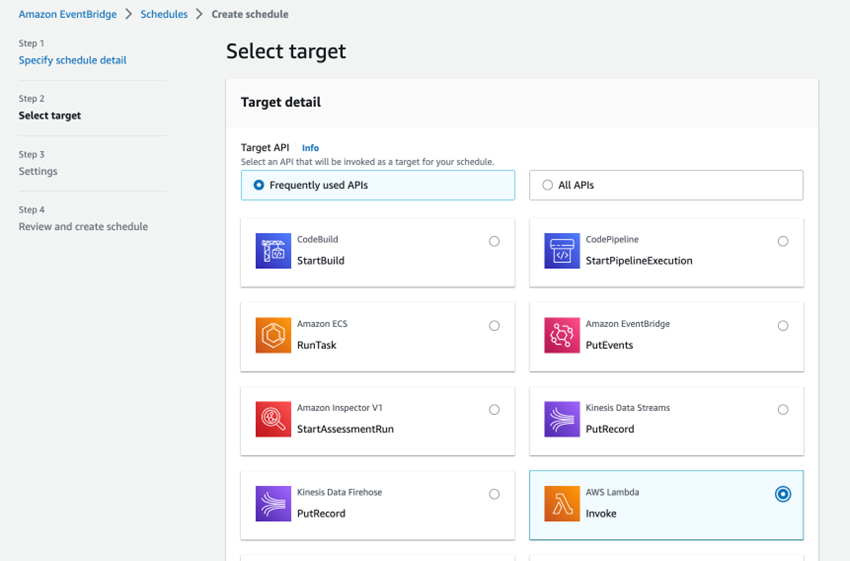
In the invoke section, select the lambda function you wish to invoke, for me it’s blog3_2 and give a sample JSON input to trigger the function and then click on next,
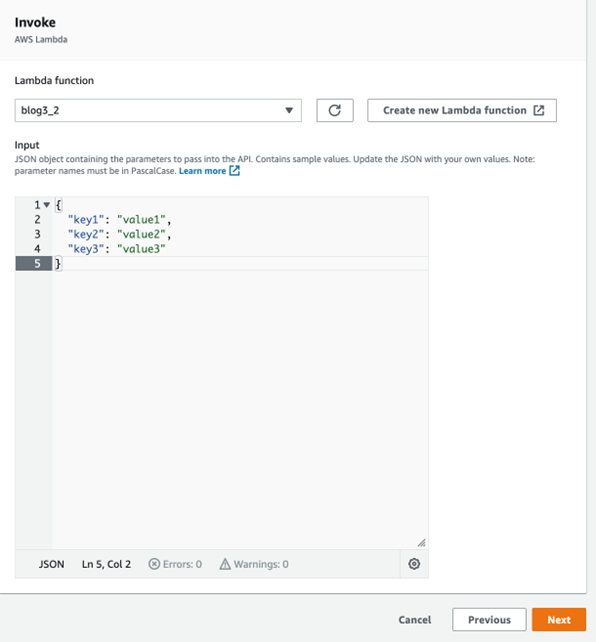
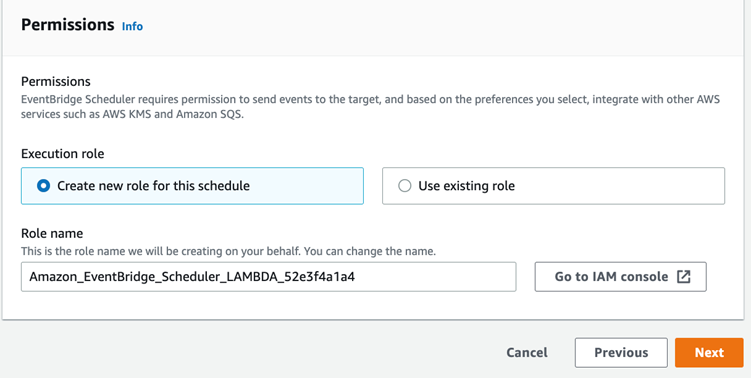
In step 3, settings, leave all options at their default selection except at the role, let the service create a new role and then click next.
Note: We can assign the policies to give permissions to do the required actions as discussed in the IAM section.
In step 4, review all the information and click on create a schedule,
For demonstration, I created a rule called “blog3rule”,
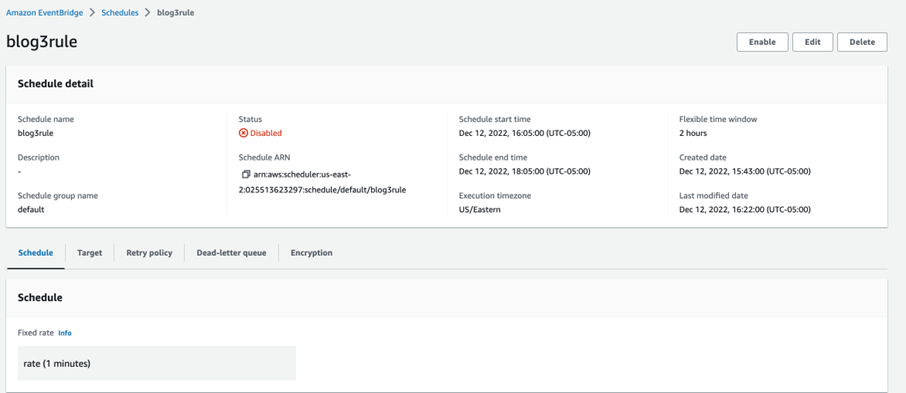
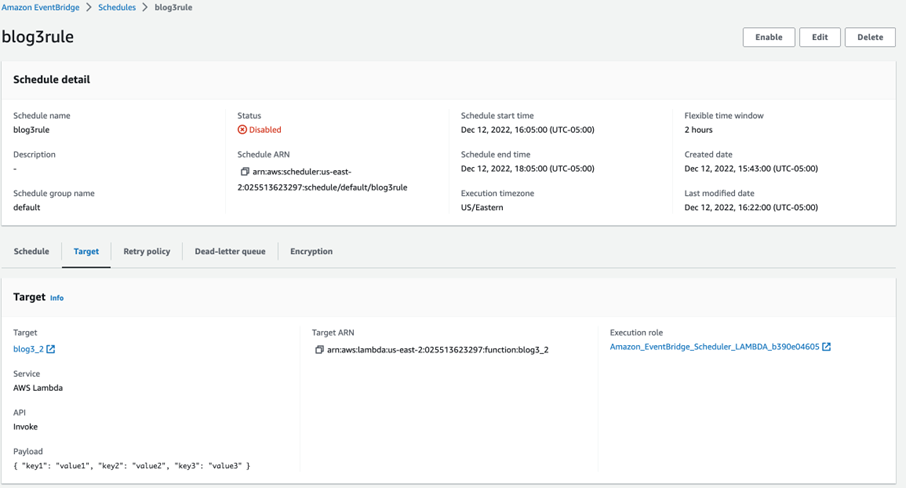
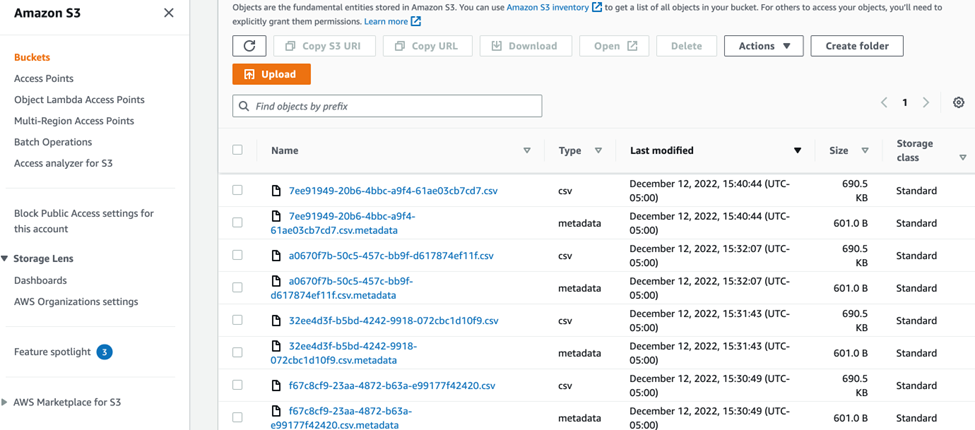
Result:
The lambda function was scheduled to be invoked every 1 minute for the scheduled time interval. As we can see below, the CSV file and its metadata are in the S3 output bucket every 1 minute which proves that our lambda function is invoked every 1 minute as scheduled.